ON THIS PAGE
## Introduction
If you're using Firebolt's Compute Optimized compute clusters, you'll see a performance boost. Firebolt has migrated the Compute Optimized compute cluster family from AWS c6id instances to c7gd Graviton instances.
The new instances offer better CPU performance, DDR5 memory (50% higher memory bandwidth), and higher network bandwidth. The migration is transparent to users, your compute clusters will automatically upgrade during normal operation with no downtime (see "Migration process" below).
This post covers how these improvements translate into real-world results, why Firebolt started with Compute Optimized compute clusters, and the technical challenges involved in the migration.
## Graviton Performance
Migrating to Graviton requires careful validation to confirm real-world gains before committing infrastructure resources. Firebolt used two approaches: (1) replays of actual customer workloads and (2) performance benchmarks.
For real workloads, Firebolt uses "customer workload replays." A compute cluster is created with two clusters, one on x86 and one on Graviton, and users' historic queries are run on their actual data (DQL only). The same query ID is assigned to both runs to enable head-to-head performance comparison.
Using historic queries, Firebolt ran tests across the entire fleet and confirmed improvements over the x86 instances currently in use. Tripledot is a great example: they're heavy users of Compute Optimized compute clusters, and their workload showed consistent improvements.
.png&w=3840&q=75)
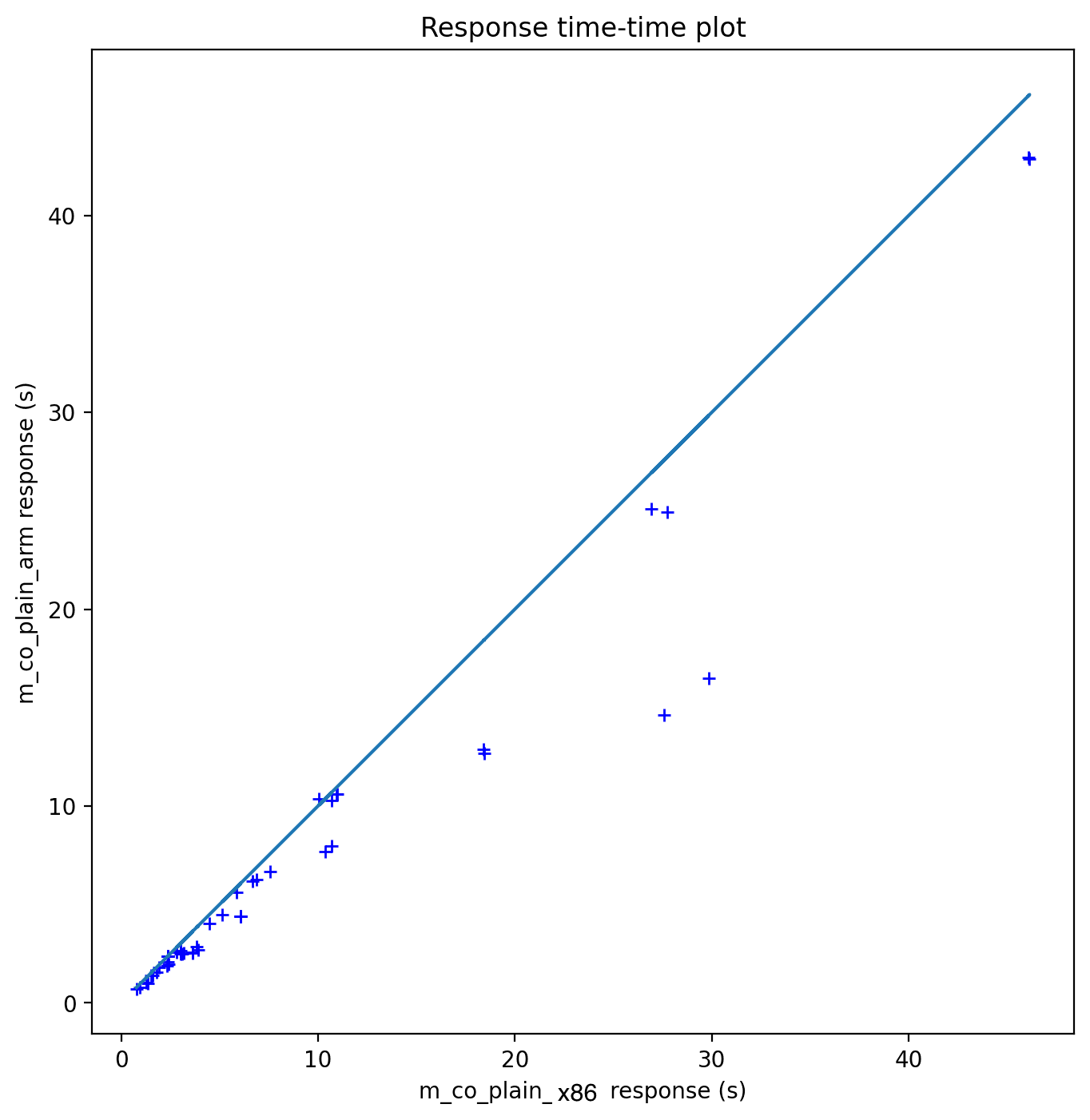
Firebolt also measured performance using a benchmark. TPC-H with a scaling factor of 100 was run on an M-sized Compute Optimized cluster, comparing x86 and Graviton head-to-head. As the chart below shows, some queries improved significantly while others moved modestly. Even when a query regressed, it was minimal (within 2%), while many saw substantial improvements.
## Why not all Compute Cluster families?
Firebolt aims to deliver best-in-class performance across all compute cluster families, but real-world constraints apply. AWS availability varies by instance family and region, and some Graviton types may not be available at all in certain regions. If there is high demand and low availability for specific instance families, there is a risk that AWS may not be able to provide the necessary compute resources.
There are two specific concerns:
Slower compute cluster starts: Firebolt maintains warm pools, idle instances kept on hand to immediately assign to workloads when you start compute clusters. If AWS can't supply new instances quickly enough, Firebolt can't replenish the warm pool after engines start.
Start failures under shortages: If a warm pool is exhausted, Firebolt falls back to on-demand instances. During shortages, your compute clusters could fail to start entirely if AWS cannot provide them.
To ensure a reliable experience, Firebolt deliberately chose to only migrate families to instance types with sufficient availability and performance. This limits the use of old generation hardware (high availability but low performance) and certain new generation hardware (high performance but low availability).
Compute Optimized is the only compute cluster family where both availability and performance requirements are met for migration. Firebolt will migrate Storage and Memory Optimized compute clusters once availability improves for the newer hardware.
## Challenges Moving to ARM
Getting a binary running on Graviton sounds as simple as compiling for ARM, right? For performance-critical applications, the reality is more complex.
### Physical Cores vs vCPU
Both c6id.2xlarge and c7gd.2xlarge list 8 vCPUs in AWS specifications. However, c6id.2xlarge achieves this by hyperthreading 4 physical cores into 8 vCPUs, while c7gd.2xlarge has 8 physical cores that directly translate to 8 vCPU.
This changes how work contends for resources and can cause increased lock contention.
### SSE2 Intrinsics
static_assert(CACHE_LINE_SIZE % sizeof(__m128i) == 0, "CACHE_LINE_SIZE must be multiple of __m128i");__m128i is the 128-bit integer vector type used by SSE2 intrinsics, so it won't compile on non-x86 processors at all (SSE2 is an x86/x86-64 SIMD instruction set).
### Floating Point Differences
Floating point calculations are inexact by definition, and Intel and ARM CPUs can yield slightly different but equally valid results. Any correctness testing has to account for that, while still ensuring that results are valid.
Casting from real literals to decimals gives different results in ARM and x86_64:3e28+999999999999999999 becomes either: - 30000000001000002375798226943.999999160 - 30000000001000002375504989174.9191999287e28+999999999999999999 becomes either: - 70000000001000000708277174272.000000430 - 70000000001000000708242972357.100888494`exp` gives different results in ARM and x86_64:exp(6.5) becomes either: - 665.1416330449221 - 665.1416330443618exp(5.1) becomes either: - 164.0219073000141 - 164.0219072999017`cbrt` gives different results in ARM and x86_64:cbrt(2435.5) becomes either: - 13.454349693900086 - 13.454349693900085### SIMD Path Fallback
In the x86 code, Firebolt sometimes uses special SIMD paths with fallbacks to standard C++. The special SIMD path performs specific instructions very quickly. The fallback should produce the same result but isn't as optimized. However, during this testing we found some non-optimised edge cases on fallback, never previously used, that would have produced different results, which allowed us to improve the code.
## How Did We Migrate
The goal was simple: a non-disruptive, transparent upgrade. If all you notice is that queries start running faster mid-workload, the migration succeeded.
Firebolt uses the same mechanism relied on for online upgrades, with one difference: instead of switching to a new binary version, the underlying instance types are switched.
Online upgrades work by creating new clusters to replace old ones. Within a cluster, parameters can be changed, including instance types. The upgrade flow:
- Provision warm pools for the new instance types (running double capacity during the migration).
- Create shadow clusters on the new instance types for each running cluster.
- Mirror all traffic to the shadow clusters.
- Wait for shadow cluster performance to match the main cluster by warming caches (via mirrored queries and automatic cache warmup).
- Cut traffic over to the shadow clusters so your workload continues on the new architecture.
Right after the cutover, your compute clusters are upgraded in-flight without disruption, and new queries get an immediate performance boost.