


.svg)
Firebolt unit is a normalized measurement of consumption.
Indexes & Reuse
Innovative subresult-reuse and specialized indexes support the most complex and demanding AI and Data Applications at high load.
Efficient Run-Time
Firebolt’s configurable execution engine delivers millisecond response times over TB datasets, by leveraging query optimization, distributed processing, multi-threading, vectorized processing, tiered caching and resource aware scheduling and scaling.
State-of-the-Art Optimizer
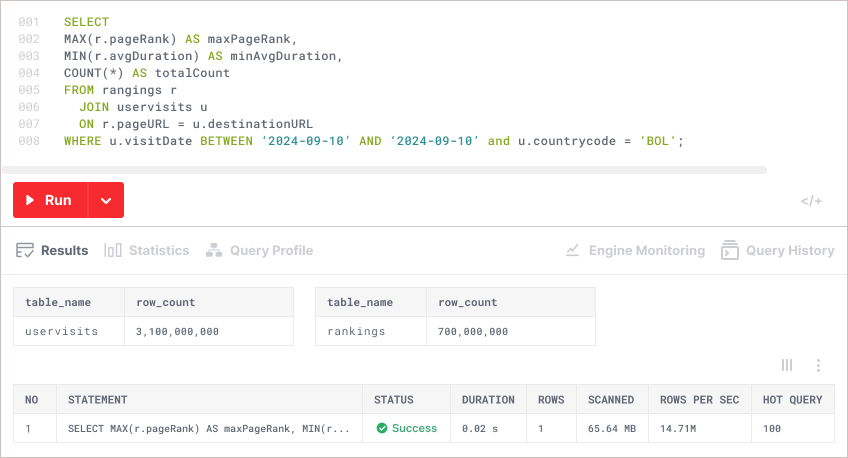
Firebolt’s query optimizer dynamically refines SQL execution by analyzing data distribution, indexing, and historical query patterns—optimizing performance for complex joins, high-concurrency analytics, and AI-powered applications.





.png)
.png)
.png)
.png)





