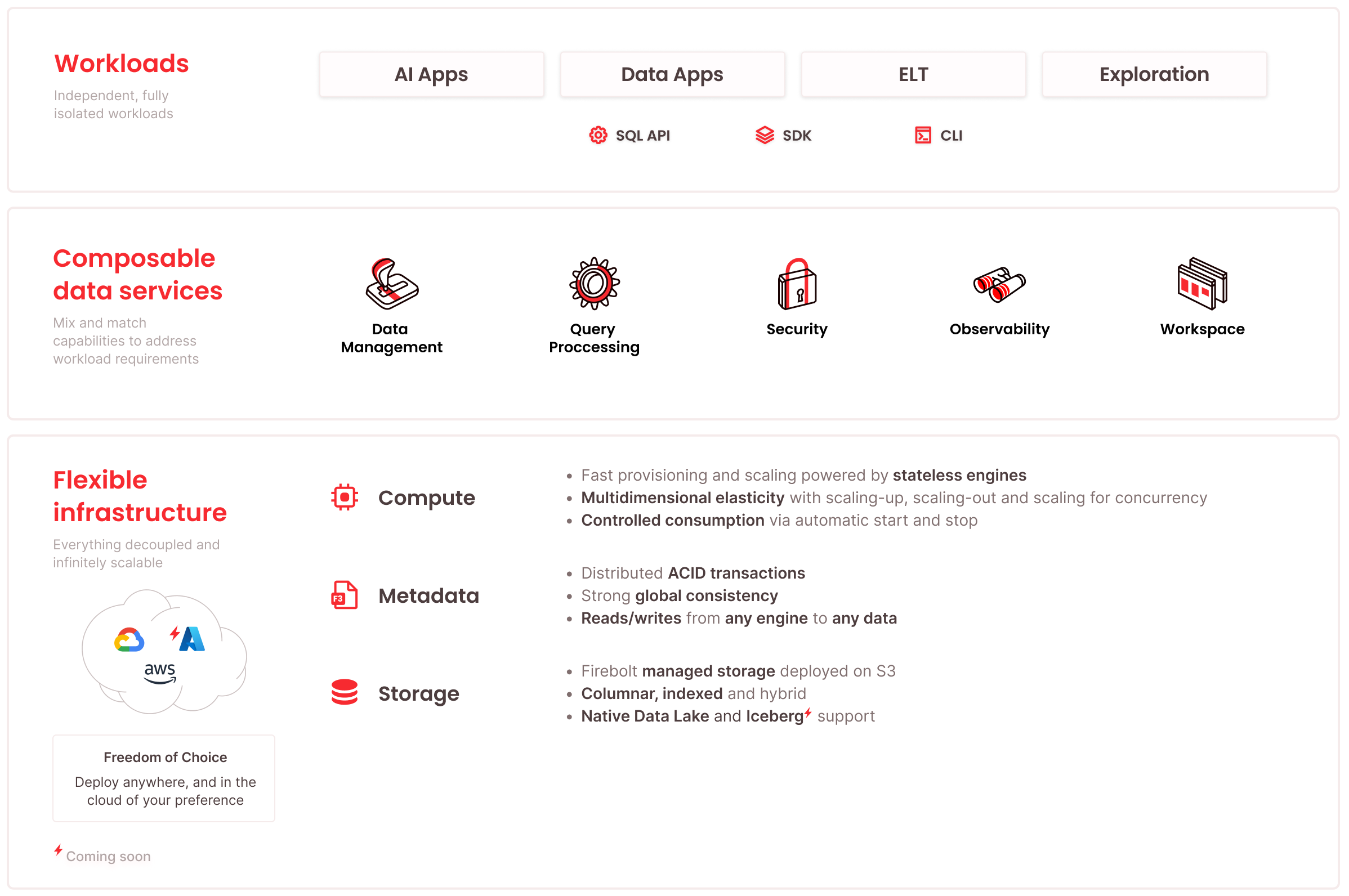


Compute Service
Firebolt’s on-demand, stateless engines scale dynamically, from 1 to 10 clusters and 1 to 128 compute nodes per cluster, ensuring seamless scale-up, scale-out, and concurrency scaling. Workloads run on single or multiple read-write engines accessing shared data, optimizing cost, performance, and isolation. A SQL-first API simplifies engine management and online scaling, powering high-performance analytics and AI applications with minimal operational overhead.

Metadata Service
Firebolt’s metadata service ensures strong consistency, transactional integrity, and seamless scaling across distributed nodes, clusters, and engines. It enables isolated reads and writes from any provisioned cluster while enforcing security and observability. With information_schema objects, metadata access is streamlined for simplified management and ecosystem integration.

Storage Service
Firebolt’s managed storage combines block storage speed with object storage scalability, using tiered storage, adaptive prefetching, and a columnar format with sparse indexing for efficient data pruning and rapid queries. With Apache Iceberg support and direct querying of open formats (PARQUET, JSON, CSV, TSV, AVRO, ORC) on S3 via external tables, Firebolt easily integrates with data lakes. Optimized for AI applications and analytics workloads, it delivers high-performance querying at scale.






