ON THIS PAGE
## Shifting (Fuzzing) Strategies
At Firebolt, we prioritize software security, as detailed in our previous blog. We employ fuzzing at the class level for our query processing and data ingestion stack, utilizing popular fuzzers such as AFL++ and libFuzzer.
Beyond dynamic testing, our security measures include static code analysis and hardening release binaries with stack buffer overflow and Control-flow Integrity (CFI) checks, Position-Independent Executables (PIE), and FULL RELRO to impede runtime exploits.
Given Firebolt's rapid innovation and expanding adoption, our security strategies must constantly evolve. The launch of Firebolt Core in 2025—a free downloadable query processor that can be hosted anywhere, and our READ_ICEBERG TVF—which allows querying data from S3 Iceberg catalogs, represent significant advancements. These developments also required us to pivot our security-testing strategies, and this blog outlines how we addressed those needs.
## Existing Challenges
Interfaces such as COPY FROM and Table Valued Functions are a gateway for untrusted user inputs. And since they constitute such a big part of a data warehouse's attack surface, we specifically wanted to fuzz them ahead of the critical releases.
But before we talk about how or what we did, let's understand why we got there.
Popular fuzzers like AFL++/libFuzzer are coverage guided, gray-box fuzzers. They instrument their target at compile time to collect in-process coverage feedback, and use that feedback to drive mutations and explore newer code paths.
However, we found these fuzzers unsuitable for our targets due to:
- Simpler Interfaces: They typically feed mutations to a target's STDIN, or write to a file that they expect the target to open/read automatically.
- Class level harness: These fuzzers mostly require a glue code that can call the target interface over a simple API–quite like unit tests. Even though AFL++ supports binary mode fuzzing (if source code isn't available), it still expects the target to accept inputs as mentioned earlier.
- Blind Mutations: They mutate inputs solely piggybacking on coverage feedback without being aware of the target's internal structure, or any knowledge of the format.
But that's not saying we didn't look under the hood:
AFL++ has a feature called Dictionaries, that relies on a user-provided list of tokens inserted at random positions during the mutations. It then observes if or how re-positioning/changing those tokens affect the coverage, long before it spews a correct input.
Therefore, such discrete tokens still wouldn't generate a syntactically correct (yet corrupt input) 100% of the time. The original author of AFL++ discussed how Dictionaries work and addressed the limitations in one of his blogs.
In recent years, however, a lot of security research have been done on how to make gray-box fuzzers structure aware using context-free grammar (thanks to Chomsky hierarchy)
Academic projects like AFLSmart have built smart mutators that claim to preserve complex file formats. Similarly, syzkaller— a popular Linux syscall fuzzer provides its own formal grammar definitions to fuzz syscalls.
But grammar fuzzers too rely on accurate data modelling. AFLSmart for e.g., uses the Peach modeling for file formats it needs to fuzz. And translating complex file-formats— especially with tightly coupled, binary structures to custom grammar requires upfront investment of time and effort, with future maintenance overheads.
The closest we could resonate with was LLVM libFuzzer's structured fuzzing approach. It exposes an interface LLVMFuzzerCustomMutator, which allows writing custom mutation logic.
For e.g., say you wanted to preserve a starting magic byte ('H') in a corpus of string values ("Hi", "Hello", "Haaaai"..) and forward the remaining to libFuzzer's generic mutator from that interface.
#include <iostream>#include <cstdio>#include <cstring>void target_func(char* Data, size_t Size){ std::string str(Data, Size); std::cout << "Post libFuzzer mutations: " << str << " \n" << std::endl;}// Forward declarationextern "C" size_t LLVMFuzzerMutate(uint8_t *Data, size_t Size, size_t MaxSize);// LLVMFuzzerCustomMutator mutates bytes in-placeextern "C" size_t LLVMFuzzerCustomMutator(uint8_t *Data, size_t Size, size_t MaxSize, unsigned int Seed){ std::string s(reinterpret_cast<char*>(Data), Size); std::cout << "Prior to libFuzzer mutations: " << s << " \n" << std::endl; // We retain the first byte ('H' in this e.g.), // and call libFuzzer's generic mutator return LLVMFuzzerMutate(Data + 1, Size, Size + 100);}extern "C" int LLVMFuzzerTestOneInput(uint8_t *Data, size_t Size) { // Additional logic can be added here, // to check for format correctness // before calling target API target_func(reinterpret_cast<char*>(Data), Size); return 0;}When libFuzzer calls LLVMFuzzerTestOneInput to pass mutated data to the fuzz target, we can additionally check if the magic byte is preserved.
Such an approach is used to fuzz libPNG.Compiling and running the above code, we see that the mutations always start with an 'H'.
// Compile with libFuzzer:~$ clang++-18 libfuzzer_custom_mutate.cpp -o libfuzz -fsanitize=address,fuzzer// Input seed:~$ cat libcorp/*.txtHiHelloHaaaai// Run:~$ ./libfuzz libcorp -runs=2000 -seed=10INFO: found LLVMFuzzerCustomMutator (0x6152e56f09c0). Disabling -len_control by default.INFO: Running with entropic power schedule (0xFF, 100).INFO: Seed: 10INFO: Loaded 1 modules (20 inline 8-bit counters): 20 [0x6152e5737f00, 0x6152e5737f14),INFO: Loaded 1 PC tables (20 PCs): 20 [0x6152e5737f18,0x6152e5738058),INFO: 3 files found in libcorpINFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes..............Post libFuzzer mutations: H�EEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEPrior to libFuzzer mutations: H�EEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEPrior to libFuzzer mutations: H�HPost libFuzzer mutations: H�HHPrior to libFuzzer mutations: HwPost libFuzzer mutations: HwPrior to libFuzzer mutations: H:@@Post libFuzzer mutations: H:@@@But our challenges were still, quite different:
- Query based API: Unlike traditional fuzz targets that read from STDIN or open/read a file automatically, our target reads the mutated file only after it receives a query over HTTP. To integrate existing fuzzers with such a pipeline would mean fiddling with their existing child process communication interfaces, such as a pipe in the case of AFL++.
- More Structure than just "Magic Bytes": Unlike other binary formats like ELF or PNG, complex DWH file formats like Parquet or Avro go beyond header magic bytes.
Parquet— for instance, contains variable length Footer metadata. Corrupting this will lead to parsers rejecting most inputs, and also won't allow us to stress paths that read the pages based on this metadata (we actually found a bug using this approach).
And to preserve this metadata, you'd first need to read the actual size of the metadata from an adjacent 4-byte field!
Given all of the above considerations, we decided to write a custom fuzzer that does what we really need:
- create partially-corrupt, yet structurally correct file formats
- write them to a path the engine can read from
- issue HTTP queries to trigger ingestion.
This approach yielded immediate values:
- We fuzzed the product holistically without having to build or maintain multiple class-level harnesses, reducing future engineering overheads.
- We built the world's first Iceberg fuzzer (to our best knowledge).
- It discovered 5 critical bugs in all of our file-format TVFs– including READ_ICEBERG!
And most importantly– we are now open-sourcing it, for the larger Iceberg and database community to test their own reader implementations.
## Introducing FuzzBerg
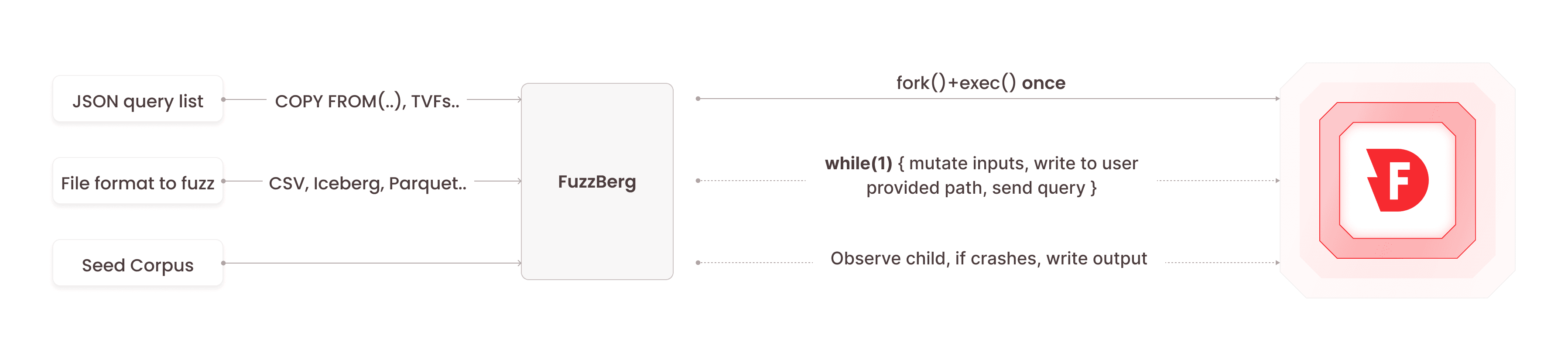
FuzzBerg is a hybrid, file-format fuzzer: it combines structured and black-box mutations (using the classic Radamsa), to fuzz database interfaces that read complex file-formats.
A Mersenne Twister seeds the Radamsa mutator, and randomises the corpus selection.
Radamsa is typically used as a CLI tool, but after a little bit of tinkering we discovered that they do support a static library mode, and incorporated that into our fuzzer's build process. It isn't structure aware, but it serves our purpose because we provide custom mutation logic (wherever necessary) on top of Radamsa.
The fuzzer is designed with modularity to allow for extensibility and ease of maintenance:
- Custom Format Mutators: Each file-format is fuzzed through a corresponding class, encapsulating mutation logic tailored to that format.
- Fuzz Target: To integrate with the fuzzer, a target implements its class that overrides two virtual methods:
- ForkTarget(): Manages the child process creation.
- Fuzz(): Calls the corresponding mutator based on the file format to be fuzzed.
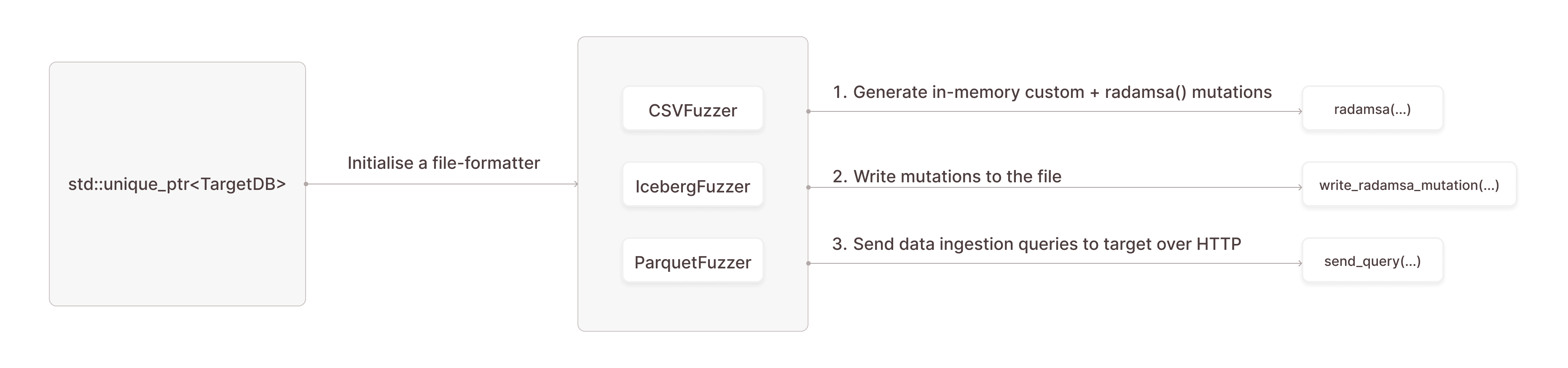
This modular approach allows for the easy addition of new file formats, mutation strategies and new targets that ingest data over HTTP based queries.
And if you own the target code like us, you can increase the odds of bug detection by:
- compiling target with AddressSanitizer
- registering a SIGHANDLER in the target's entrypoint, that calls __gcov_dump() when it receives a SIGUSR1 from the fuzzer. We did this to analyze coverage after a fuzz campaign and write better mutation logic, but it's also a great way to visualize post-fuzzing coverage statistics.
## Alright, let's talk some file-format fuzzing now
## Fuzzing Iceberg
Apache Iceberg is a popular open table format for efficient querying data without storing them in a data warehouse. For brevity— it comprises three Metadata layers, followed by the actual Data layer. When a specific version of data is queried, the reader parses each metadata layer sequentially to return the results from Data layer in the most efficient way:
- Layer 1: JSON metadata
- Layer 2 & 3: Avro metadata (manifest list and manifest files)
- Layer 4: Parquet data
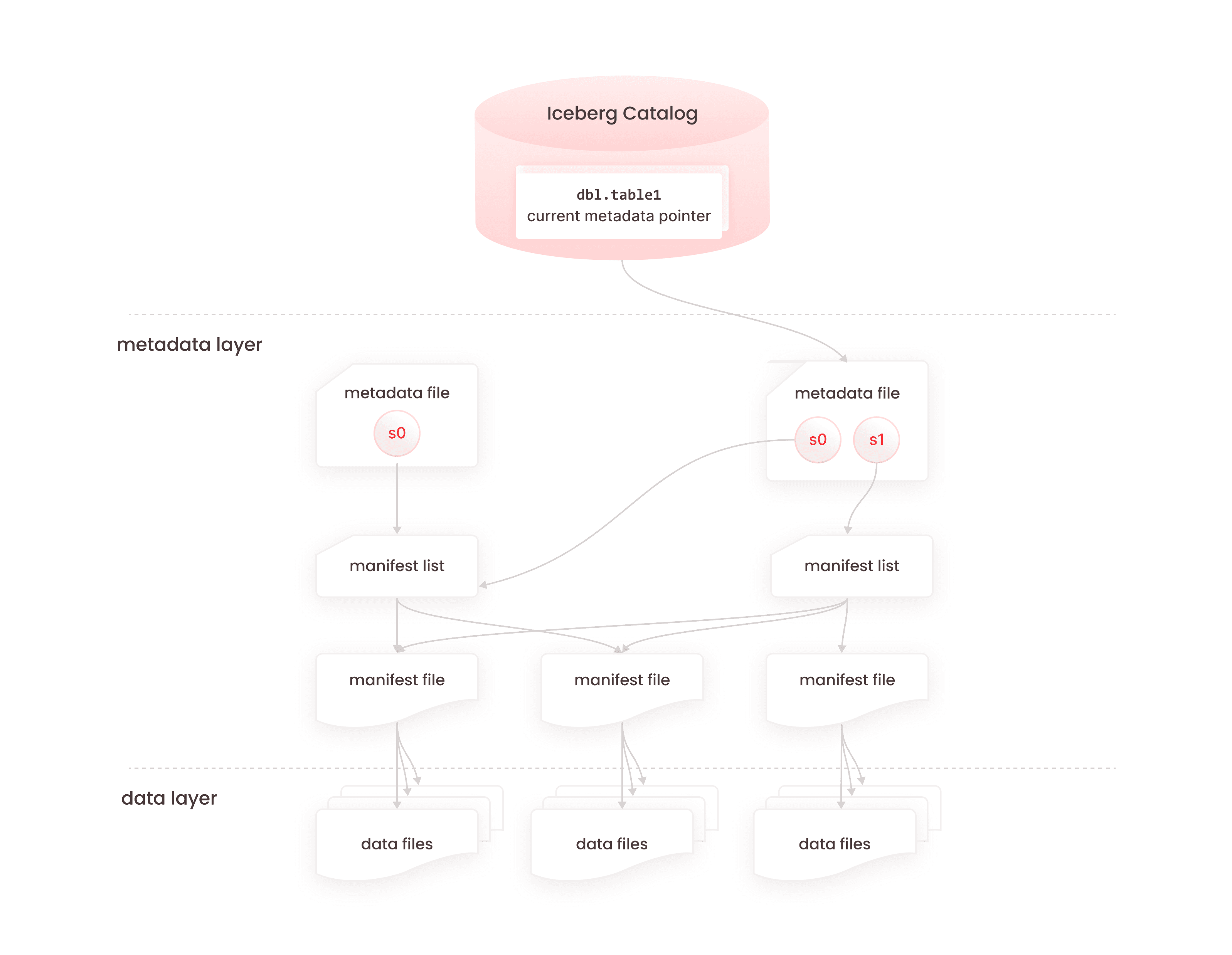
Iceberg's official spec says every layer has some mandatory fields (that we need to preserve in the mutations), while some are optional (which we probably can remove).
Since our Iceberg seed corpus is generated on S3, we do some in-process modifications before handing it to the format fuzzer. We de-serialize the original seed into a nlohmann JSON object, and then modify the following:
- Update "location" field to a local Minio path
- Remove "metadata-log" (if exists) as we are not interested in metadata time-travel
- Remove "snapshot-log" (if exists) as we are not interested in snapshot time-travel
- If a "snapshots" list exists, we update every "manifest-list" field inside (to a local file that the fuzzer writes the Avro mutations to in Step 3 below).
Due to such complex inter-layer dependencies, and varying file formats at each layer, we take a three step, sequential approach to fuzzing Iceberg:
#### Step 1: Blind Metadata fuzzing
We pick a random seed from the updated metadata corpus, and let Radamsa mutate it as is. At this step, no custom mutation logic is applied.
As Radamsa is not structure aware, it flips random bits and duplicates bytes, which allows us to validate our JSON parsers.
Original Metadata (trimmed):
"table-uuid":"371589cb-27dd-4622-bc18-acc423d1e1be"}
Mutated Metadata:
"Table-uuidz":"371589cb-27dd-4622-bc18-acc423d1e1-bc18-acc423d1e1be"}be"}be"}be"}be"}
But interestingly, Radamsa isn't completely dumb either! It sometimes goes deep into the nested fields to selectively alter values (maintaining type correctness too), such as in the case below:
Original Metadata:
{"current-schema-id":0,"current-snapshot-id":8715189102138002866,....,"schemas":[{"fields":[{"id":1,"name":"field_int","required":true,"type":"int"},{"id":2,"name":"field_int_null","required":false,"type":"int"}],"identifier-field-ids":[],"schema-id":0,"type":"struct"}],"snapshots":[{"manifest-list":"s3://iceberg-fuzzing/metadata/manifest_list.avro","schema-id":0,",..,"table-uuid":"d83c214b-5292-4c5f-827a-9d851f1a6137"}
Mutated Metadata:
{"current-schema-id":0,"current-snapshot-id":8715189102138002866,....,"schemas":[{"fields":[{"id":1,"name":"field_int","required":true,"type":"int"},{"id":2,"name":"field_int_null","required":false,"type":"int"}],"identifier-field-ids":[],"schema-id":0,"type":"struct"}],"snapshots":[{"manifest-list":"s3://iceberg-fuzzing/metadata/manifest_list.avro","schema-id":65535,",..,"table-uuid":"d83c214b-5292-4c5f-827a-9d851f1a6137"}
#### Step 2: Structured Metadata fuzzing
We re-use the same seed from Step 1, but now de-serialize the JSON to mutate every field value with Radamsa. If the field is a nested object or array, we descend further (depth=1 for now), and randomly pick a key/index to mutate, as shown below:
Field is an array, traversing further..
Field Value: [{"fields":[{"id":1,"name":"field_int","required":true,"type":"int"},{"id":2,"name":"field_int_null","required":false,"type":"int"}],"identifier-field-ids":[],"schema-id":0,"type":"struct"}] ,
Key: "type", Original Value: "struct", Mutated Value: "surstrutrvdct"
This step ensures that field names do not get mutated, so we remain compliant with Iceberg specs, and only change their values.
We now encounter a wider gamut of errors beyond invalid JSON formats, such as type (e.g. "Not a valid signed integer") and schema confusions, and we start gaining ground on the Iceberg reader.
#### Step 3: Structured Avro manifest list fuzzing
This is where things get a bit more interesting. The manifest list corpus is an immutable Avro container file format, which is part JSON and part binary encoded. It has a rich data-structure that includes magic bytes, and sync-markers to delineate blocks and mark EOF's.
We initially preserve the 4 magic-bytes ('O', 'b', 'j', '1') in the header, and mutate the remaining bytes with Radamsa.
Then, we apply a set of probabilistic custom mutations:
- Sync Marker Corruption targets Avro's 16-byte block delimiters, corrupting both initial and final markers to test parser synchronization recovery.
- Block Metadata Corruption attacks count/length fields that define data organization, potentially triggering buffer overflows or infinite loops.
- Schema Injection inserts fake JSON schema fragments to exploit schema confusion bugs where parsers might apply conflicting schemas to the same data.
- File Size Manipulation tests boundary conditions through random truncation and null-byte padding at the cost of format corruption.
- Bit-Level Corruption simulates storage corruption by flipping individual bits to catch subtle integer overflow and off-by-one errors.
- Block Duplication creates structurally valid but logically inconsistent files by reordering data blocks, exposing assumptions about block sequencing.
Such a multi-step approach allows us to target different parser components—from low-level file format handling, to high-level schema validation.
## Fuzzing Parquet
Apache Parquet is an open-source, columnar file format designed for efficient data storage and retrieval. It serves as the data layer for Apache Iceberg tables, but is also used as a standalone format for efficient query processing in various big data analytics frameworks.
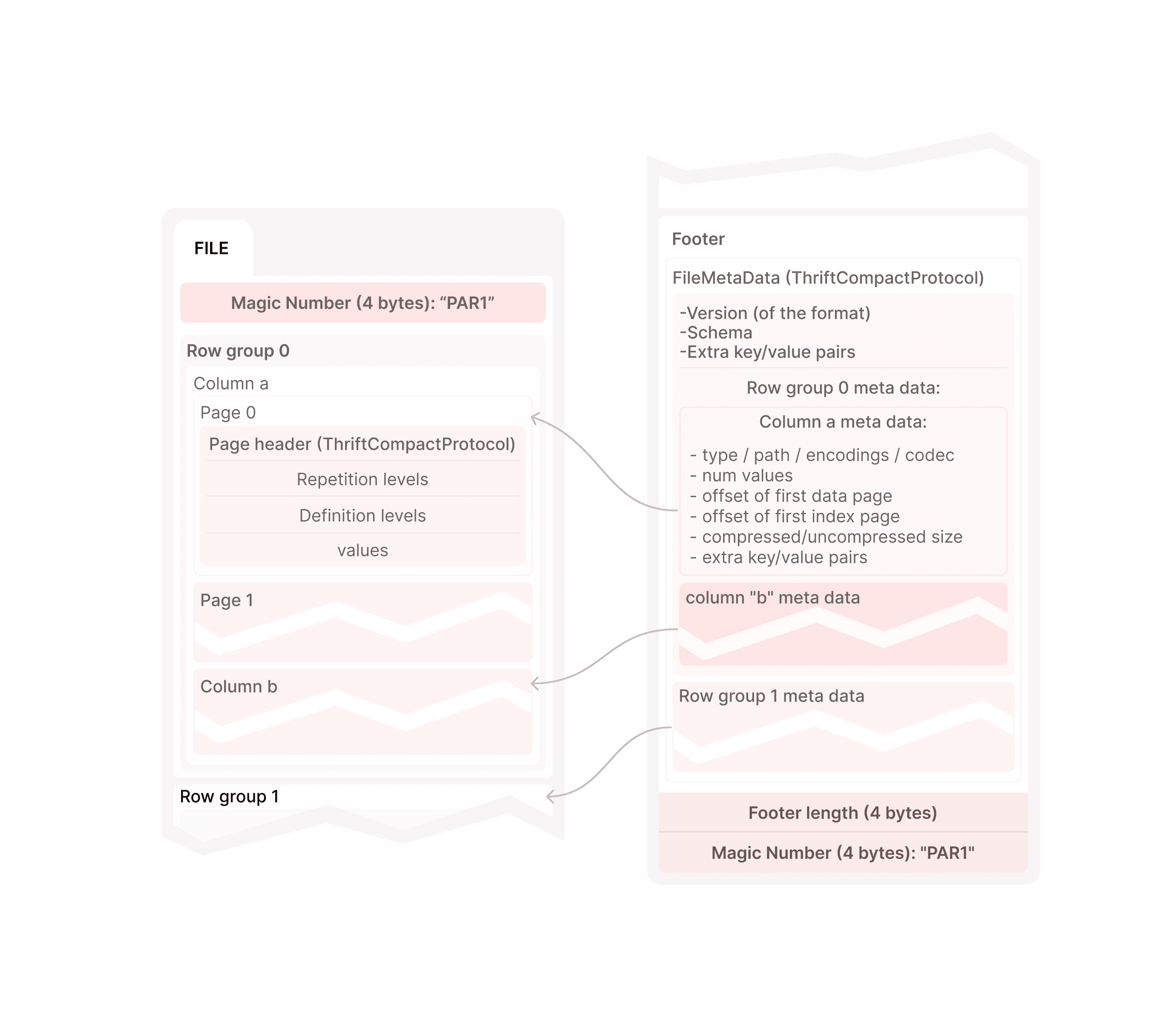
To fuzz Parquet, we preserve the following sections in a legitimate seed:
- 4 x 2 magic bytes in header and footer ("PAR1"),
- 4-byte footer (contains the size of Footer metadata)
- Variable sized footer metadata (File + Row group metadata)
We also perform some additional checks on the validity of the Footer metadata size, so as to ensure that the fuzzer itself does not crash from bad allocations.
The remaining bytes (page header metadata and data pages) are then fed to Radamsa. Post mutation, we recreate the Parquet format by stitching up the header, mutated pages and footers for ingestion.
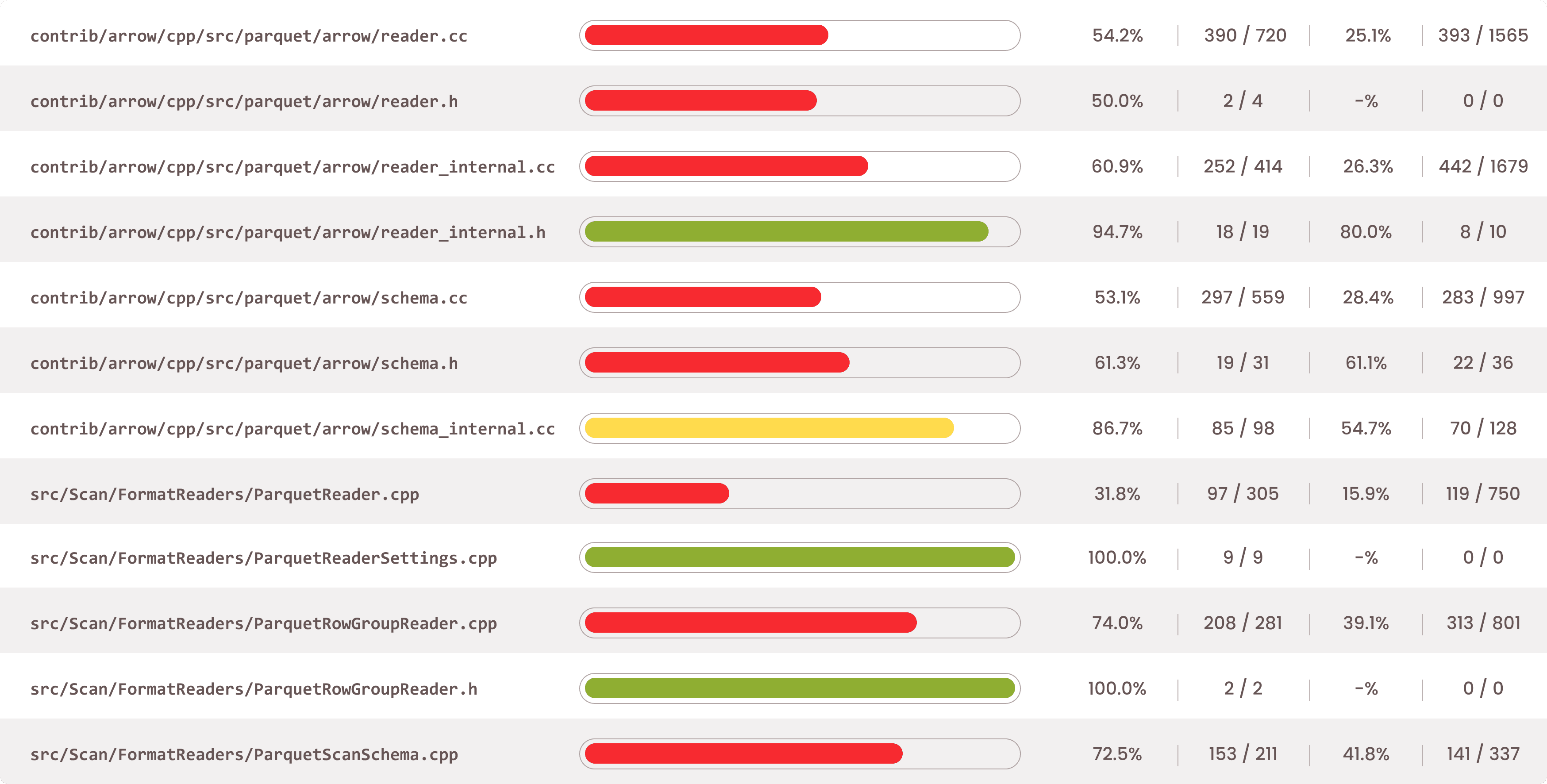
Fuzzing our Parquet interfaces (READ_PARQUET and COPY FROM) for about an hour yields >60% median BB coverage, and ~40% of branch coverage in some of the most critical reader code-paths.
Our custom logic for mutating data pages, while maintaining essential structures trigger a diverse range of errors**:**
- Schema corruptions: (e.g. Cannot infer internal type from "map", Failed to read schema from 'fuzz.parquet': Couldn't deserialize thrift)
- Page Header Metadata vs Data conflicts: (e.g. IOError: Number of decoded rep / def levels do not match num_values in page header)
- Compressions errors: (e.g. corrupt Lz4/Snappy compressed data)
- Corrupted data pages: (e.g. Received invalid number of bytes (corrupt data page?) )
## Discoveries
During a total runtime of less than a week, the fuzzer discovered 5 critical bugs impacting all our TVFs:
- READ_ICEBERG (also affected our READ_AVRO): An OOB index read while parsing Avro manifest-list.
- READ_CSV: an assertion failure in Arrow's CSV parser, leading to a buffer overflow. The bug was caught and fixed earlier by the upstream maintainers, but was still present in Firebolt's Arrow version.
- READ_PARQUET:
- A logic bug in our Parquet reader, triggered via a SIGABRT on a code path that should otherwise have been unreachable.
- A logic bug on parsing empty chunks led to a buffer overflow in Arrow's binary array parser.
- An OOB read due to an incorrect logic that attempted to read more rows in a Page column than was specified in Parquet file metadata.
## Further Improvements
As a prototype, this fuzzer exceeded our expectations in terms of quickly discovering some deep nested bugs. But as with all fuzzers, there is room for improvements:
-
Better Execs/sec: With all the overheads of structured fuzzing and a long ingestion pipeline, the fuzzer was expected to run slow. While speed was not the main focus during the prototype, we still optimized things wherever possible: be it re-using cURL handles to send queries, or passing complex structures by-reference.
We also tested writing mutations to a memory backed file instead of direct writes to the filesystem, but this turned out to be slower due to higher # of expensive syscalls, such as two ftruncate() calls (before and after generating a mutation), and msync() to flush the writes to disk immediately.
-
Power Scheduling: For this prototype we don't differentiate seeds, but future research can be done on gathering runtime heuristics (e.g., unique response signatures) to assign more energy to promising seeds.
-
Iceberg fuzzer enhancements:
- Manifest layer fuzzing: We currently stop fuzzing at Manifest list layer, as we dedicatedly fuzz Parquet interfaces. Therefore, some Iceberg TVF implementations might stop reading (for optimized reads) when it cannot find the manifest file based on the "manifest-path" field value in manifest list.
Overall, the bugs we found with FuzzBerg encourage us to explore it beyond TVF fuzzing— such as stressing the SQL parser. And so FWIW, coverage guided gray-box fuzzing is not the only way to find a needle in the haystack.
Don't forget to take FuzzBerg for a spin, and we hope you enjoyed reading this.