ON THIS PAGE
At Firebolt, we are committed to delivering great software that's devoid of security bugs.
As a cloud data warehouse company, we want to provide our customers with a secure product that they can use without worrying about the safety of their data workloads. However, in the complex world of software development, maintaining robust security is a relentless challenge. More features mean more code, and therefore potential for more bugs. And to consistently weed them out from a rapidly growing codebase such as ours, relying solely on traditional testing methods like static analysis is insufficient.
This is where fuzz testing comes in.
In this part of our security blog series, we'll highlight how we fuzz Firebolt's blazing fast query processor written in modern C++- a fast, yet memory unsafe language.
### What is Fuzzing, and why is it important?
- Dynamic software testing
- Send semi-random inputs to the target binary (most often compiled with a sanitizer), hope for a crash, and then analyze the code where sanitizer reported the crash
- Catches bugs that if exploited, can lead to serious security issues. In our case, this could potentially translate to reading cross-tenant query data from adjacent memory, to infiltration and takeover of Firebolt's customer engines via an RCE
There are tons of great blogs on various fuzzers and techniques, so we will limit the details here to showcase how we employ some of them to hunt for 0-days in our product, and secure our customer workloads.
### Our approach (to Fire-Fuzzing)
Catching bugs is like finding a needle in the haystack, so effective fuzzing starts with picking the right targets. Fuzz targets are typically interfaces that directly receive and parse external user inputs. As a distributed data warehouse, a lot of our code is also heavy on parsing. To establish an effective fuzzing process at Firebolt, we identified those critical parts in our software, and tailored respective strategies around them. The following sections dive into some of those details.
User input enters Firebolt in two main ways:
- SQL statements (DQL/DML/DDL)
- Customer data loaded from S3 (using our COPY FROM / EXTERNAL TABLE features)
The first type of user inputs are processed by the SQL compiler, while the second type by various File formatters (depending on the file type being ingested, eg. CSV/JSON/Parquet).
### SQL compiler
To fuzz the SQL compiler, we run two different frameworks in parallel:
- AFL++ to primarily fuzz the frontend SQL parser
- A custom SQLsmith extension (privately maintained) to stress the later stages
For AFL++, we maintain a harness code linked against a LocalExecutor library which encapsulates our in-process SQL query processor, seed the fuzzer with a subset of DQL, DML and DDL statements from our continuous SQL test suites, and use its persistent mode to call the target function "executeQuery()" with the fuzzer generated strings.

Most of the time the fuzzer generates inputs that the SQL parser rejects due to incorrect grammar- and that's okay. Lexer rules are also written to handle invalid SQL strings, so we still manage to crash the target and find memory bugs from time to time such as double-free and heap OOB reads, especially in classes that deal with invalid SQL error handling.
With SQLsmith, we add another dimension to SQL fuzzing, as it can generate grammatically correct statements that the parser accepts, yet still find bugs deeper inside the query processing stack (Planner, Runtime).
The upstream version supports PostgreSQL and other PG compliant databases (e.g. sqlite and MonetDB). Since Firebolt strives to maintain SQL dialect compliant with Postgres, we were able to extend SQLsmith with minimal changes by:
- importing upstream under our private GitHub org
- implementing Firebolt classes to connect and fetch schema (col names, data types)
- overriding the dut_base::test() function to send SQLsmith generated queries to Firebolt
- catching the HTTP responses (when not a 200 OK) with SQLsmith's internal error handler, which it uses internally to track error types to mutate AST's and generate fuzzing stats.
Being PG compliant, we were also quickly able to piggyback on the existing implementations for registering most of our supported SQL functions with the corresponding args and return types.

SQLsmith works by connecting to the target database, fetching schemas, and recursively creating random ASTs with schema info and registered Firebolt SQL functions/operators while keeping the grammar intact. The AST's are then converted back into their equivalent SQL string representation and sent to the target database for execution. If the response returned is logically inconsistent, or the server crashes, it records a bug.
Additionally, in order to test boundary conditions and discover what happens when SQL constructs are pushed to their limits (e.g. longest identifier, maximum number of tables in JOIN), we use the tensile library written by our CTO Mosha. We have extended the language support in tensile for Firebolt specific SQL constructs such as lambda functions.
### File formatters
To fuzz file input formatters, we leverage LLVM's in-process fuzzer (libFuzzer) and our existing unit test suite (gtest), as reaching that part of the code by simply hammering the frontend parser won't be possible due to the invalidness of the fuzzer generated strings. For e.g., we took our gtest code for the CSV file formatter class, and re-wrote it into a libFuzzer target. To boost fuzzing efficiency, we employ techniques such as code coverage analysis (gcov), and feed off that information to guide our fuzzing campaigns.
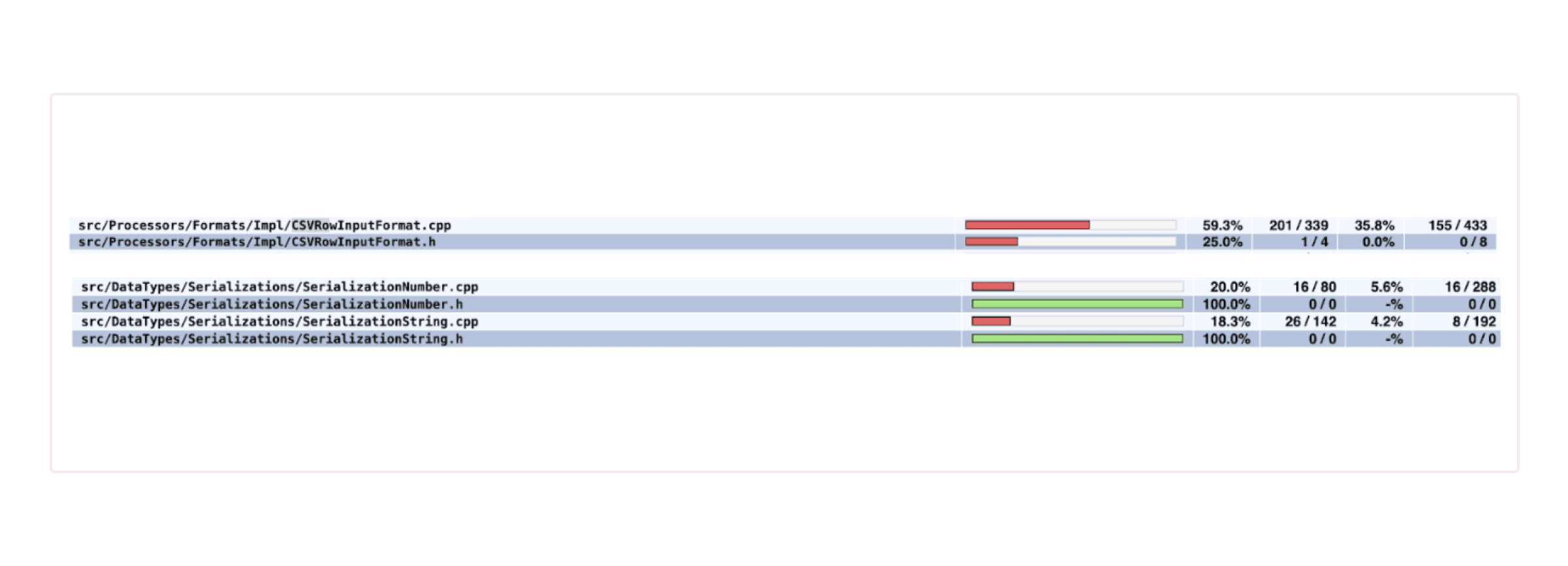
If it's not covering enough code, we study the target further to identify all possible execution paths, and the conditions under which execution flows into each of those edges. Thereafter, we take two important measures:
- Re-write the harness: We instantiate different instances of the target class with different configurations (e.g. enabling ALLOW_COLUMN_MISMATCH in one object and disabling it in the other) to cumulatively cover all the blocks and edges.
- Refine seed corpus: We seed libFuzzer with valid CSV data that adheres to each of these configurations, allowing the fuzzer to mutate these inputs more effectively and reach deeper code paths.

We also write the harness in a way that covers all data-types currently supported for that file format and seed the corpus accordingly, so that de-serializers for those data types are also fuzzed in the same campaign.
For complex data-types such as arrays, we use structured fuzzing to make sure that our target only processes inputs that are enclosed within [ ].
Using the above techniques, we managed to discover a critical heap OOB write in our CSV input formatter. It is also worth mentioning that for fuzzing with libFuzzer, we use Debug builds that enable assertion checks (_LIBCPP_DEBUG) in the standard library, in addition to instrumenting with address sanitizer. This has helped us catch buffer overflows in code while iterating over STL containers such as vectors and maps that even ASan once failed to detect (we tested this against non-Debug ASan build with the same fuzzer input).
### Reproduction, Triaging and Fix
When we discover bugs, we reproduce them both locally, and in a secure isolated environment without affecting customer workloads in Production. So far, all our findings have crashed the test engines due to illegal memory operations, thereby re-invigorating our faith in fuzzing as a sure path to shipping secure software.
Afterwards, the security research team conducts a detailed crash analysis to determine the root cause of the bug. Once an RCA is done, we follow a structured process to address the issue with engineering teams through Jira tickets.
Additionally, we publish internal research blogs after each finding to help engineering understand why the bug occurred, how it was debugged, and include suggestions to avoid similar logic pitfalls in future iterations.
In most cases, bugs are fixed within a week of discovery, with patches rolled out in subsequent releases cut-off for the Staging environment, where we re-verify the fixes before finally releasing it to Production.
### Fuzzing at scale, LLMs and beyond
We continuously improve our processes to discover bugs at a pace that keeps up with our engineering velocity. Some of these efforts include fuzzing the latest master branch in CI three times a day, with automated crash detection and uploads to a private S3 bucket at the end of each CI run.
Additionally, we've developed internal tools to automate reproduction with the crash data locally before conducting the RCA, thereby reducing significant time and manual efforts in eliminating false positives.
We are further researching the potential application of LLM in our fuzz tests, such as in the area of corpus generation for fuzzing file formatters.
Every new bug that we discover and eliminate brings us one step closer to our commitment to shipping a secure product. And at Firebolt, we enjoy that challenge every single day.