ON THIS PAGE
- Firebolt Architecture
- Fast Infrastructure Provisioning
- Managing Compute
- Multi-cluster Management
- Engines Control Plane
- Engine Architecture
- Request Routing
- Online Scaling
- Create and start a new engine cluster
- Traffic switchover
- Drain traffic from the old cluster
- Graceful drain
- Online Upgrade
- Single engine upgrade
- Upgrade verification process
- Fleet wide upgrade
- Summary
Firebolt is a next-gen data warehouse platform designed for data-intensive analytics. It provides high efficiency and low latency, allowing data engineers to deliver scalable analytics faster, more cost-effectively, and with greater simplicity. In Firebolt, an Engine is the compute resource that customers will use to ingest data into Firebolt and to run queries on the ingested data. An Engine comprises one or more clusters, where each cluster is a collection of nodes of a certain type that provides a certain amount of CPU, RAM, and storage. Among the critical capabilities that engines provide to meet the needs of modern analytic workloads are: 1/ Multi-dimensional Elasticity, which allows users to scale their engines across multiple dimensions. 2/ Granular Scaling allows users to incrementally add (or remove) nodes to their engines, and 3/ Seamless Online Upgrades, enabling users to get the latest security updates and performance enhancements without interrupting their workloads. This blog post will discuss how Firebolt implemented zero-downtime upgrades under the hood.
## Firebolt Architecture
Firebolt implements a "disaggregated shared-everything architecture" with "compute and storage separation." This architecture allows multiple compute resources running different workloads to be fully isolated from each other while sharing the same data. The visual below demonstrates the logical architecture of Firebolt.
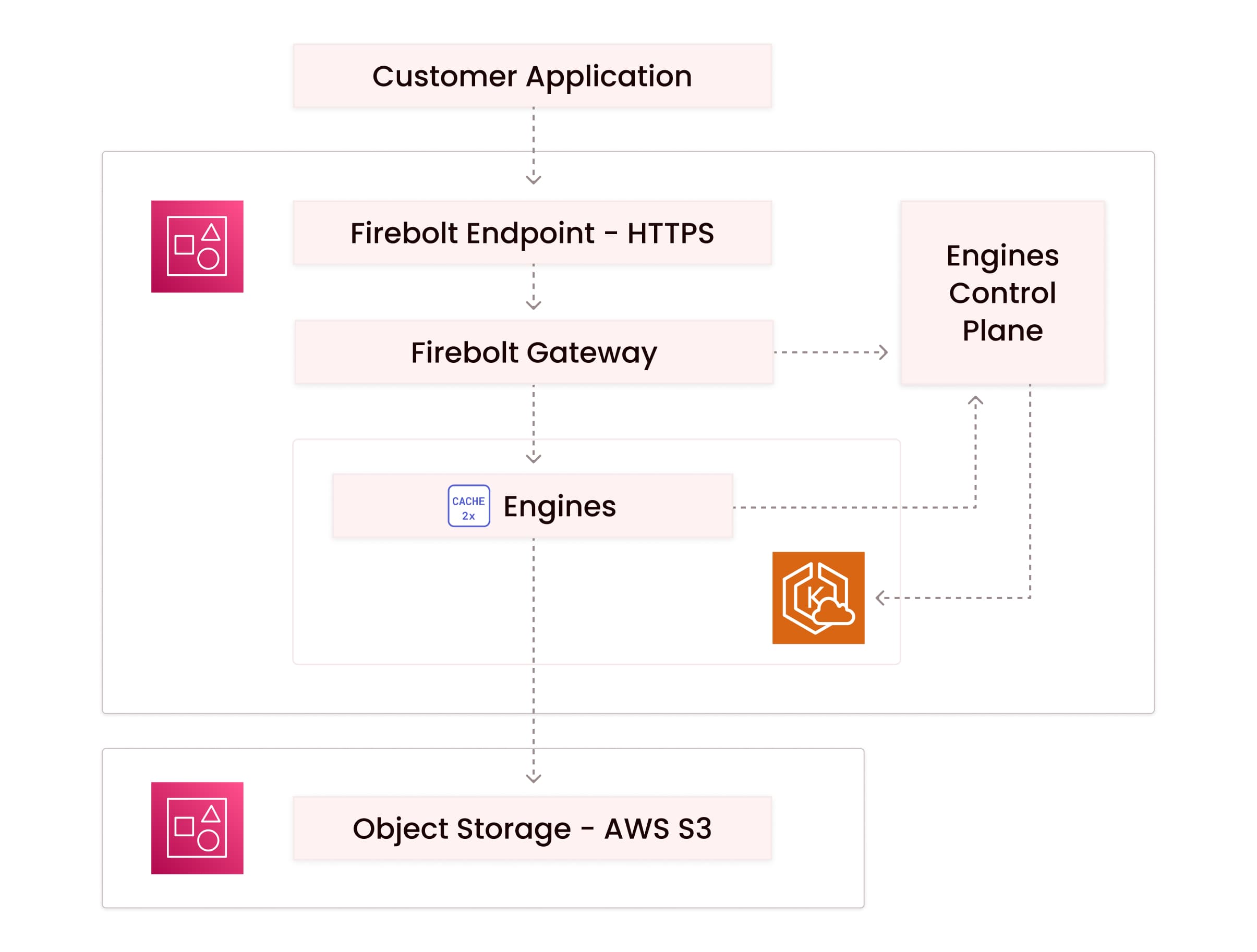
The key components of the architecture are:
- Firebolt Gateway - Responsible for routing customer requests to the correct Engine.
- Engines Compute - Clusters of machines running in Kubernetes and service customer queries.
- Object Storage - Stores customer data
- Engines Control Plane - Manages the lifecycle of engines and is responsible for provisioning, de-provisioning, scaling, and upgrading engines.
Separating compute from storage allows the compute and storage layers to scale independently, providing customers with flexibility in scaling their engines to achieve optimal price/performance for their workloads. In designing the architecture for engines, we made important design choices around the following:
- Fast Infrastructure Provisioning: Enable customers to create and scale their engines quickly.
- Managing Compute: Running engines on Kubernetes vs. EC2 VMs directly
- Multi-cluster Management: Whether to use Service Mesh for managing multiple EKS clusters
### Fast Infrastructure Provisioning
To enable customers to quickly create and scale their existing engines, Firebolt pre-provisions a fleet of compute nodes called Warm Pools. When a customer requests a new engine or wants to scale their existing engine, Firebolt leverages the Warm Pool to satisfy these requests rather than going to the underlying cloud provider, thus providing fast engine operations.
### Managing Compute
To efficiently manage the compute resources needed for engines, we decided to use AWS Elastic Kubernetes Service (EKS) and AWS Karpenter, an open-source high-performance autoscaler for Kubernetes. The built-in scaling and scheduling capabilities provided by Kubernetes and the autoscaling capabilities of Karpenter gave us a great degree of flexibility in how we dynamically manage our compute infrastructure at scale without the need to maintain raw VM fleets.
### Multi-cluster Management
As noted earlier, Firebolt is designed to meet the performance demands of today's low-latency, high-concurrency workloads. To meet these performance requirements, which can be in the tens of milliseconds, we needed a way to support multiple EKS clusters communicating with each other in a fast and secure manner. To manage these multiple EKS clusters, we used sidecar-less multi-cluster mesh to enable direct pod-to-pod OSI L4 communication between engine nodes without introducing extra hops in network communication.
### Engines Control Plane
Engines Control Plane is a set of micro-services responsible for Engine lifecycle management. The Control plane is responsible for:
- Provisioning, scaling, and upgrading engines
- Providing engine routing information
- Providing consumption & auditing information
The control plane provides a reliable workflow to manage the lifecycle of engines, interacting with Kubernetes clusters in order to provision and deprovision actual hardware resources. We use Temporal as a backend for workflow orchestration to satisfy our requirements:
- Provide reliable at-least-once execution for every workflow step.
- Provide capabilities to serialize operations on the objects of interest.
### Engine Architecture
When designing Engines, one of our key goals was to ensure we provide the latest software upgrades without any downtime for our customers. We want to deliver these upgrades to our customers at a regular cadence without requiring them to stop their engines. To deliver these online upgrades without interrupting customer workloads, we considered the two options below:
- Make changes to the engine nodes in-place while they are running (or)
- Create an entirely new set of nodes that have the latest upgrades
Although making changes in-place to an engine while it is still running helps deliver the upgrades without customers having to stop their engines, any issues arising from the upgrades could impact the performance of the running workloads. Hence, we decided to pursue the second option above, for which we leveraged engine clusters. As noted earlier, an engine cluster is a collection of nodes. We designed clusters to be immutable objects to avoid disrupting customer workloads during the online upgrades. Making clusters immutable allowed us to guarantee that we won't push configuration changes to already running clusters, which could potentially introduce unexpected and undesirable changes to customer workloads. Before we look at how Firebolt uses immutable clusters to deliver online upgrades seamlessly, let's understand how dynamic engine scaling works in Firebolt. The upgrade process is built on top of dynamic scaling.
### Request Routing
Firebolt Gateway fleet is a multi-tenant service responsible for routing requests to the correct engine and load balancing across engine clusters. Each engine cluster and each node within a cluster are individually routable. To support that, the Gateway fleet maintains an up-to-date state for each engine cluster, including:
- Cluster state (stopped, starting, running, or draining)
- Routing information for each node of the cluster
- Cluster routing strategy
Once a request lands on one of the Gateway instances, the Gateway service performs authentication engine discovery and then routes the request to the corresponding engine. Each request carries information about the engine it is targeting. At a high level, the flow for the request to reach the engine node is as follows:
- The Gateway node receives the request
- Gateway performs authentication
- Discover requested engine state and routing information
- If the engine is stopped and auto-start is enabled, start the engine
- Select the running engine cluster
- Select engine node within a cluster
- Route request to selected engine node
The logical engine layout as Gateway fleet sees it is represented below:
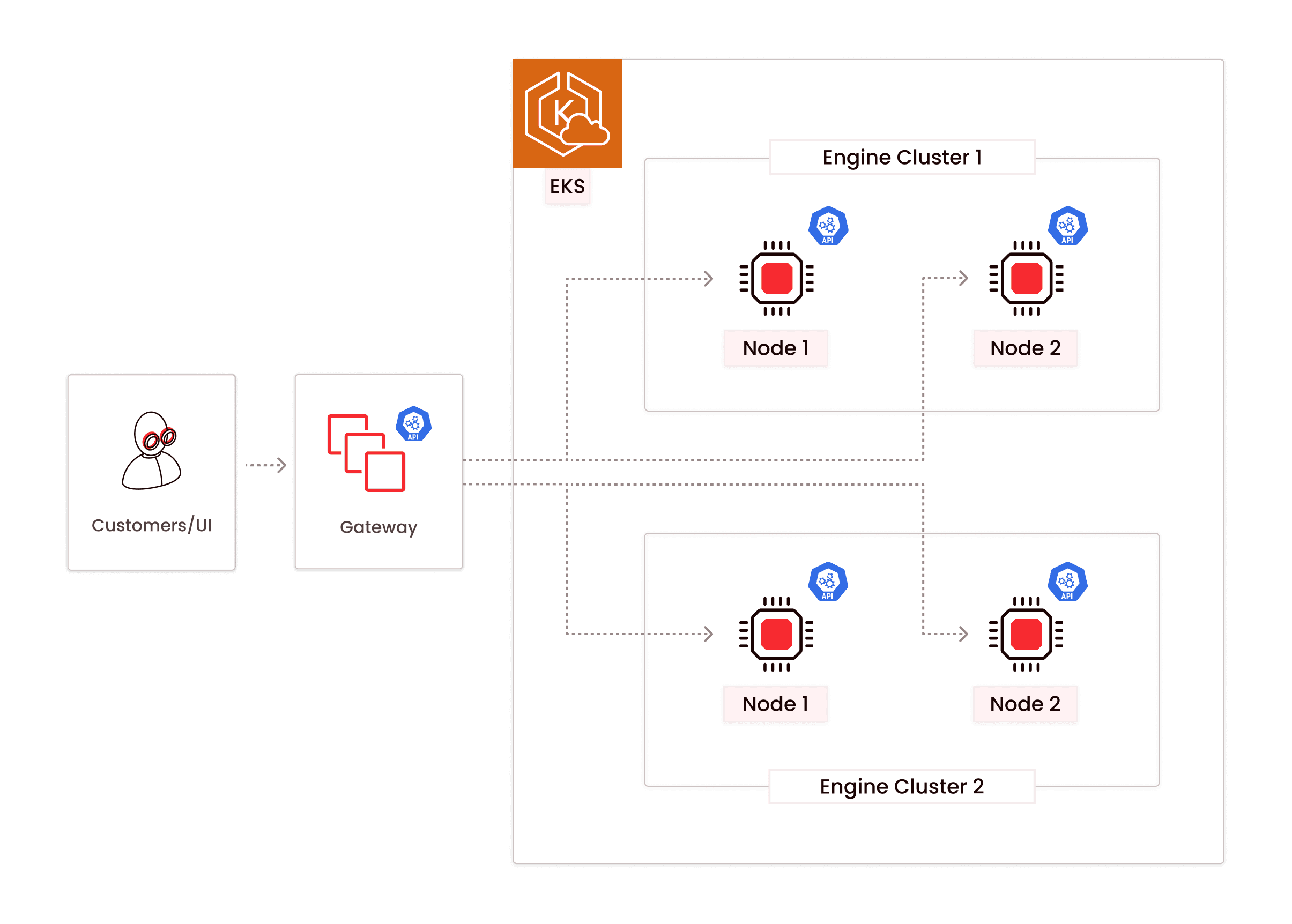
The gateway fleet is crucial for load distribution across engine clusters and unlocks online scaling capabilities. Since the Gateway fleet is on the critical query execution path, having the minimum possible request routing overhead times is paramount.
Our goal was to have sub-1ms Gateway latency overhead at p50.
To achieve that, the Gateway fleet implements the:
- In-memory engine routing information on each of the Gateway instances.
- Subscribes to notifications event stream delivered from Engines control plane for any engine cluster state changes. This increases cache hit rates by proactively populating the in-memory cache with up-to-date engine states.
In the unlikely case of a cache miss, Gateway will explicitly fetch fresh Engine routing information from the Engine's control plane via a synchronous request.
## Online Scaling
The Control Plane for Engines drives the process of online scaling of any engine.
The process to scale an engine:
- Create a new engine cluster and start it
- Switch traffic over to a new cluster
- Drain the old cluster and stop it
- Delete old cluster
To ensure the scaling process does not cause downtime, the Gateway fleet and Engines control plane work together to avoid traffic disruption. Gateway fleet receives up-to-date state from the Engines control plane regarding the state of each engine cluster. Using this information, Gateway selects the appropriate cluster for sending traffic and avoids disrupting the queries running on the old clusters. The Engine's control plane tracks whether an engine cluster has any active queries before shutting it down during the drain phase.
We'll demonstrate the scaling process in more detail by scaling from a 2-node engine cluster to a 3-node engine cluster. The scaling process along other dimensions (changing the node Type or the Number of Clusters) is conceptually the same.
All operations in Firebolt can be performed via SQL or UI. When the user first creates an engine with the SQL command below, Firebolt will start with a 2-node engine cluster receiving customer traffic:
CREATE ENGINE MyEngine IF NOT EXISTS WITH TYPE = S NODES = 2;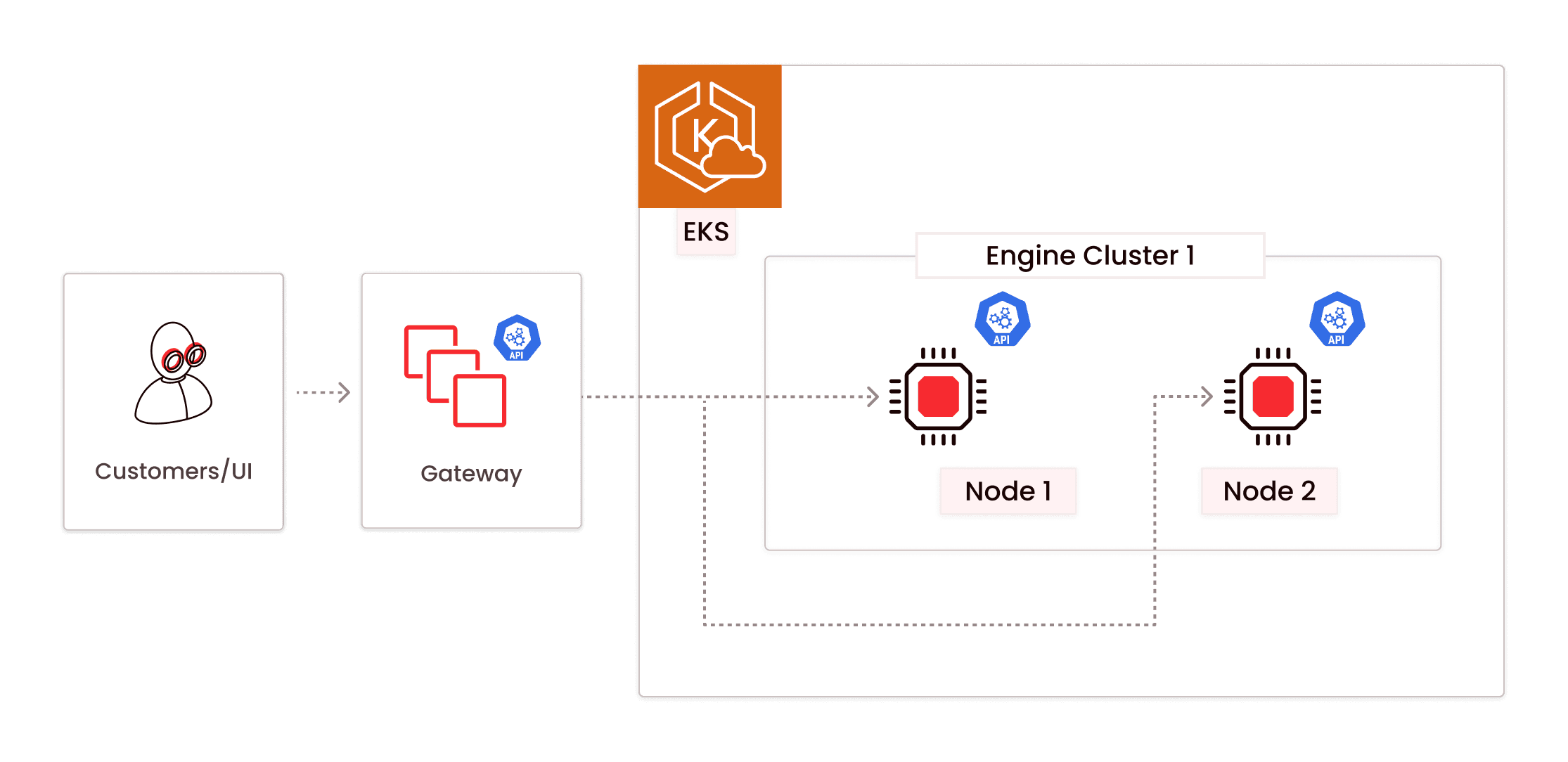
As the workload continues running, let us say that the user wants to scale out their engine from a 2-node cluster to a 3-node cluster to meet their performance demands. They can easily do so using the following SQL command:
ALTER ENGINE MyEngine SET NODES = 3;The below visual shows what this scaling process looks like in Firebolt.
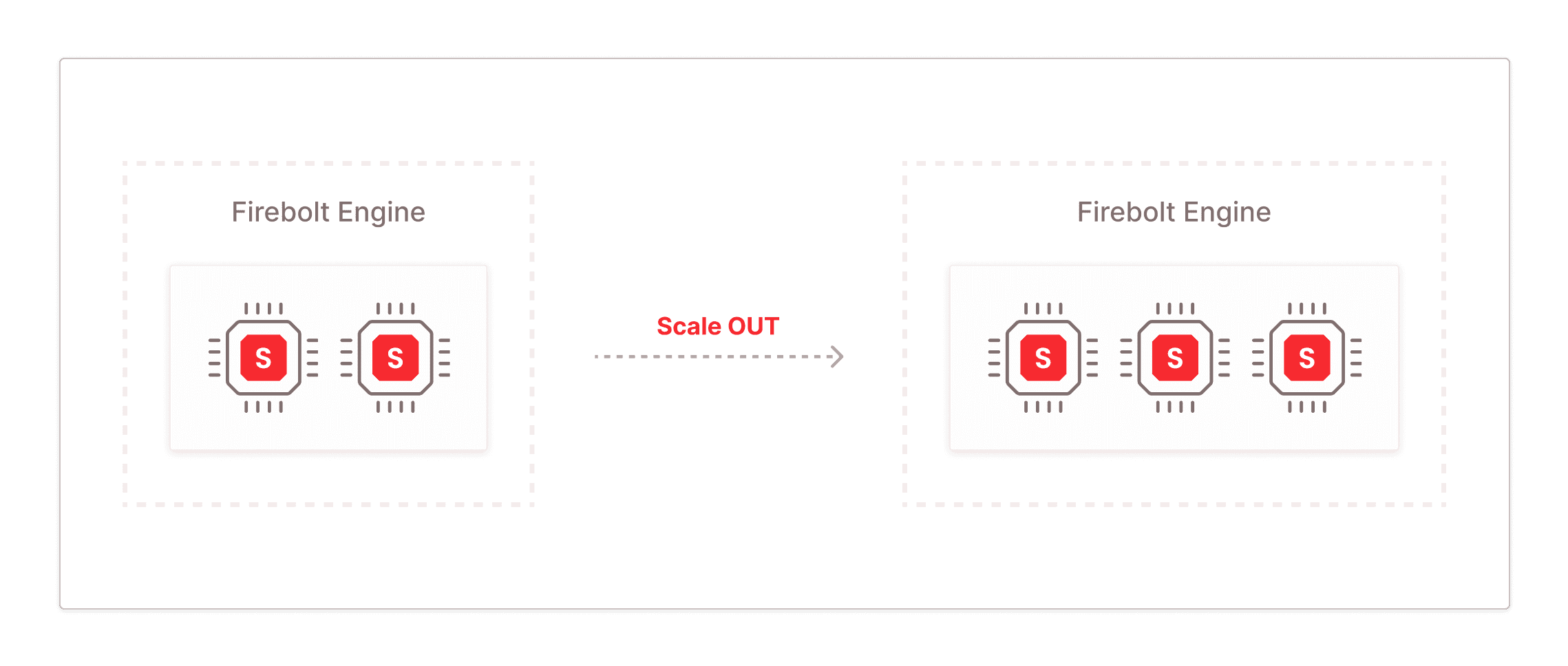
Now, we will go under the look and look into the details of this scaling process:
### Create and start a new engine cluster
- A new 3-node engine cluster is created.
- Control Plane starts the cluster and updates its state to RUNNING once it's up and running.
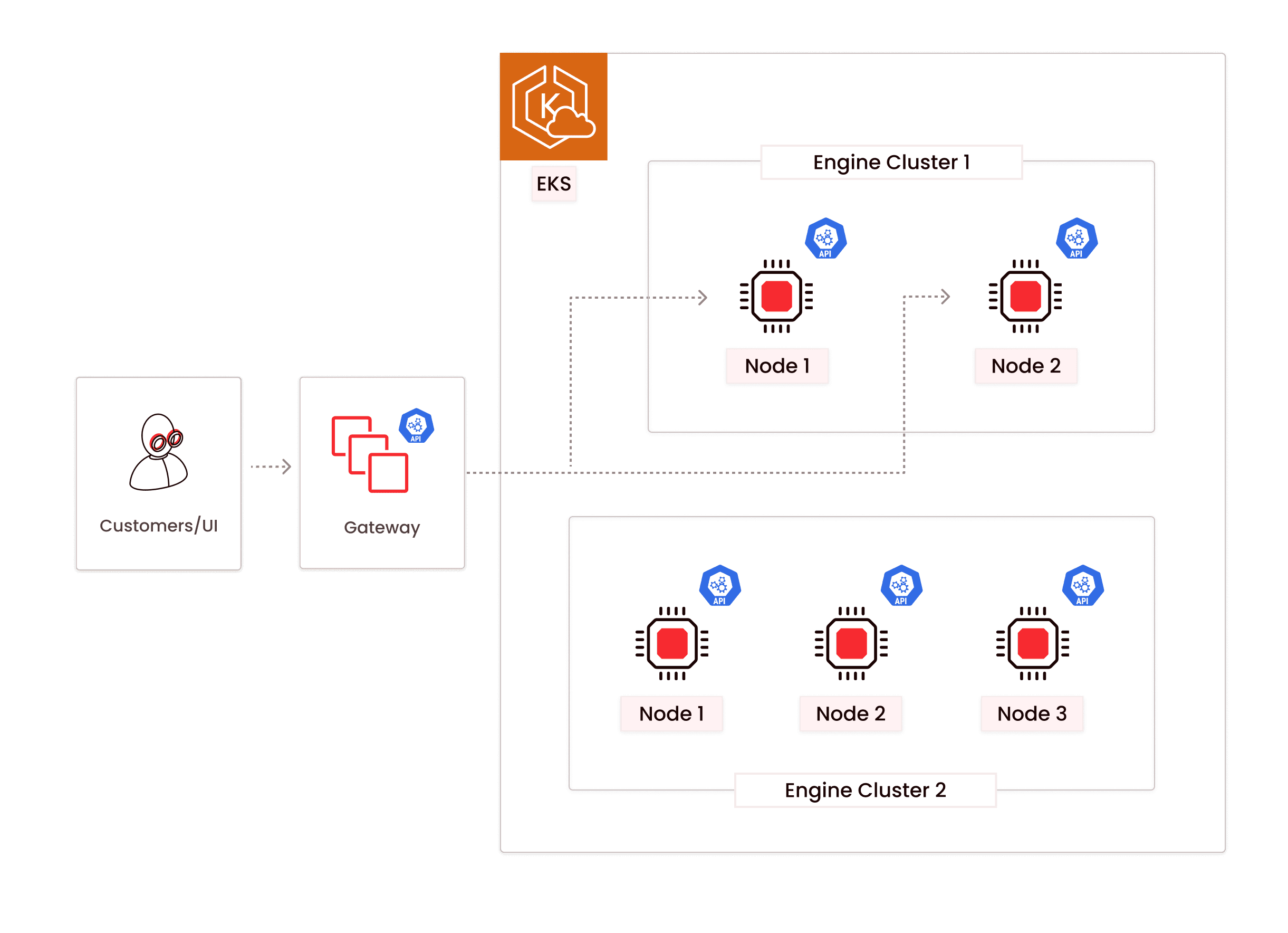
### Traffic switchover
- Gateway fleet receives a notification from the control plane stating that the Engine state has changed.
- The Gateway fleet starts routing traffic to the new cluster.
- The Engines control plane switches the old cluster to a draining state
- The gateway fleet receives a notification stating that the engine state has changed and detects that the old cluster is in a DRAINING state. The Gateway fleet stops sending traffic to the old cluster.
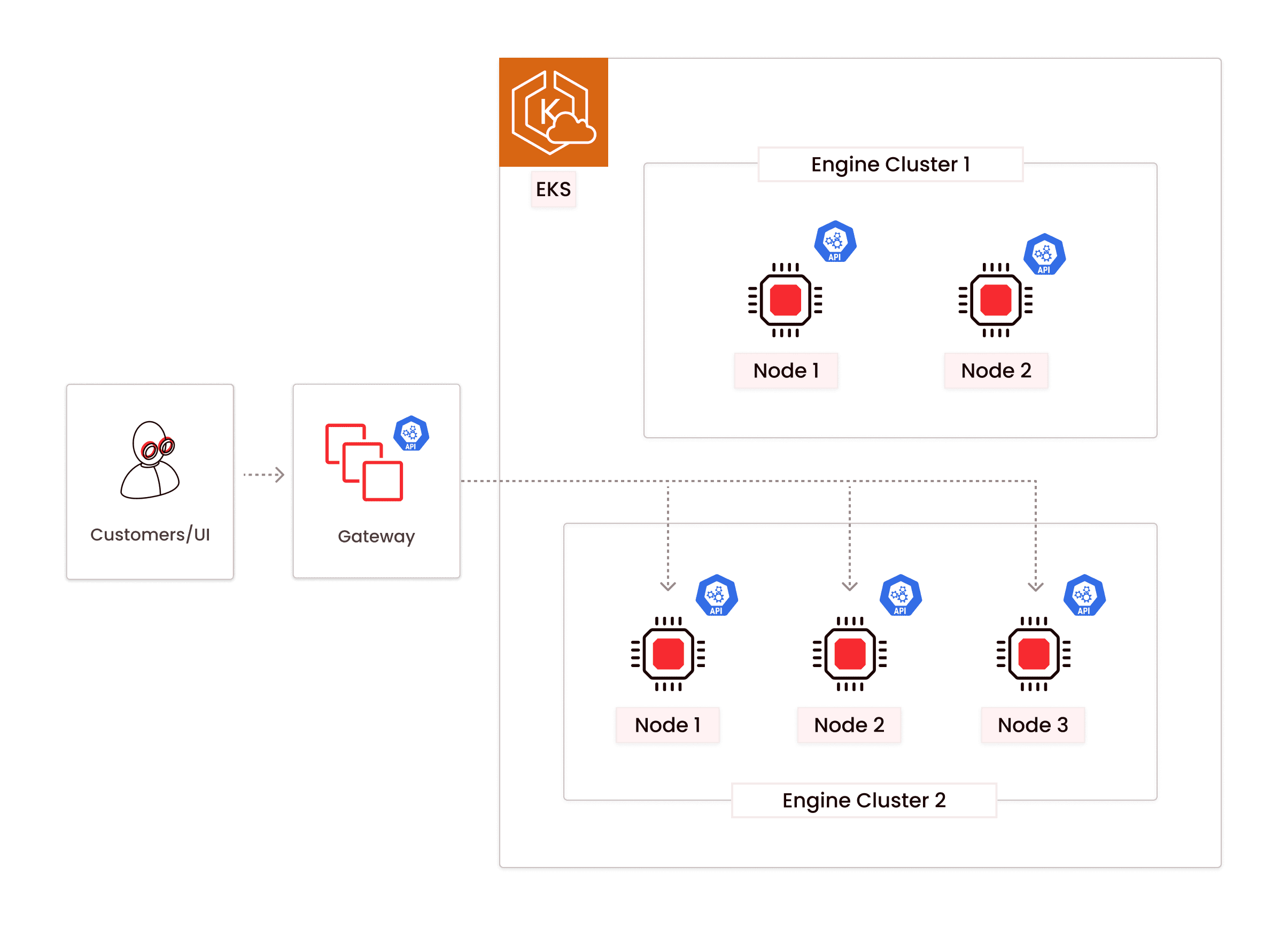
### Drain traffic from the old cluster
The Engine control plane tracks the number of queries running on the old cluster. Once the number of active queries reaches zero, it invokes engine cluster shutdown.
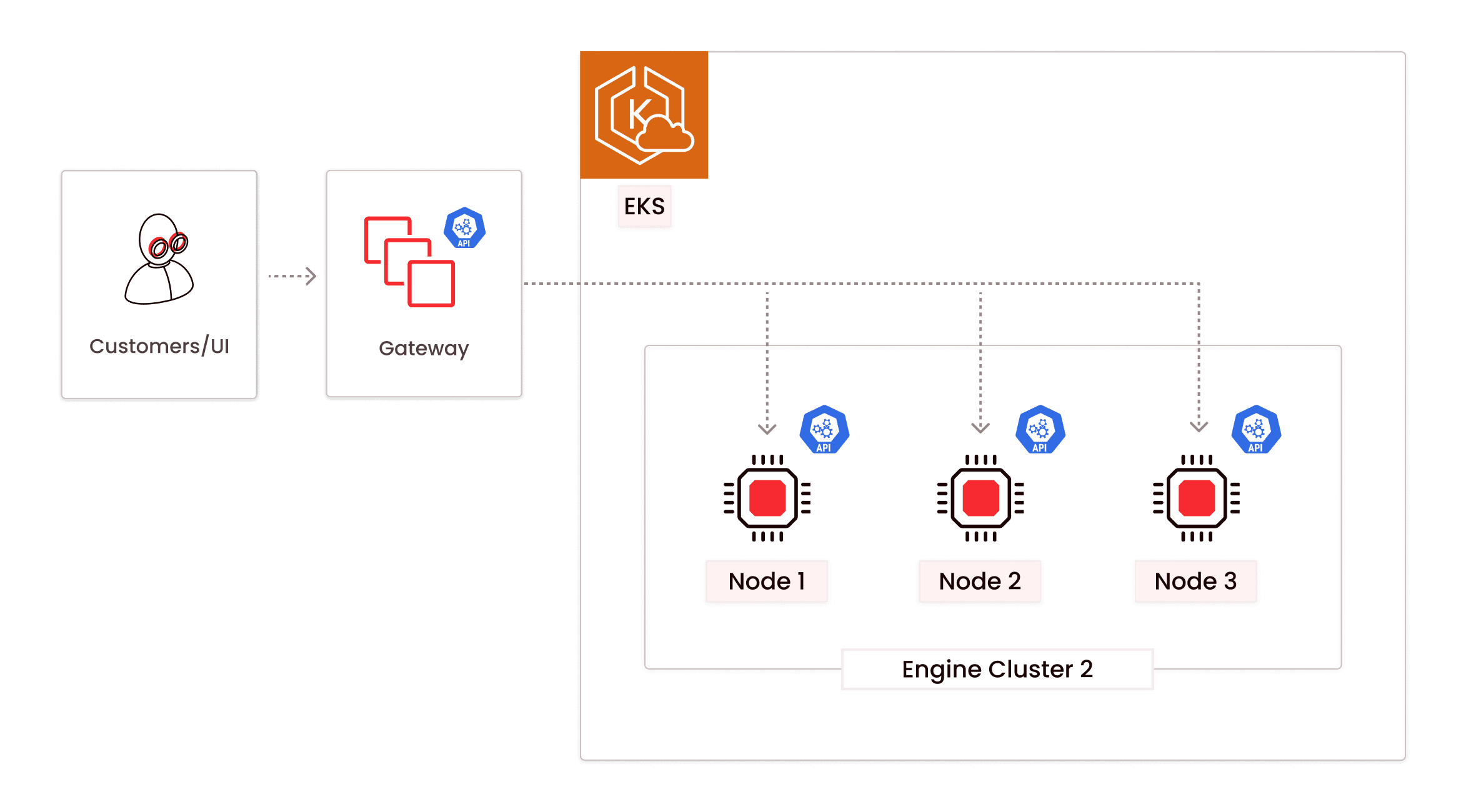
These operations allow Firebolt to perform "blue-green style" deployment when changing engine shape to the specification requested by the customer.
### Graceful drain
As mentioned above, old clusters are gracefully drained during online scaling before shutting down. This is necessary to ensure queries running on an engine when the engine was scaled to a different configuration can be completed successfully.
Steps to execute graceful drain:
- The Engines control plane marks the Engine Cluster as DRAINING. It sends notifications about the state change.
- The gateway fleet receives an engine state notification, detects a draining cluster, and removes it from the list of clusters eligible to receive traffic.
- Any new query that reaches the Gateway fleet will be routed to engine clusters that are still RUNNING.
- The control plane watches the number of running queries on the cluster that are being drained. Once no running queries remain, the control plane invokes the engine cluster destroy sequence that removes underlying Kubernetes resources and engines cluster metadata.
We had several options for how graceful drain would check for running queries:
- Waiting for each engine node to notify the control plane when it has no active queries
- Rely on Kubernetes graceful drain mechanism to self-shutdown each node once no running queries remain
- Making control plane poll engine cluster for the number of running queries
Each engine cluster performs distributed query processing. Engine cluster nodes have to be running to execute distributed queries. Because of that, individual nodes could not make a shutdown decision, and the control plane had to coordinate the process. We opted for the third option of the control plane polling the cluster. It coordinates the shutdown sequence and reduces the amount of traffic flowing from each engine cluster to the control plane during normal system operations.
## Online Upgrade
Firebolt leverages both online scaling and graceful drain to perform engine upgrades.
### Single engine upgrade
The Control Plane is driving the engine upgrade process. It takes a sequence of steps:
- For each engine cluster, the Control plane creates a new shadow engine cluster with the same specifications as the old one, except a new Firebolt database version is used. The control plane starts a shadow cluster.
- Control Plane changes engine traffic configuration to mirror mode. Any request to an engine cluster is mirrored to the corresponding shadow cluster. Routing is performed to ensure the same load distribution on primary and shadow clusters.
- Gateway fleet receives new traffic configuration and starts traffic mirroring.
- The upgrade verification process starts.
- The upgrade process waits for verification to finish.
- If the verification result is a success, the upgrade process performs promotion.
- The promotion process makes the shadow a new primary and starts a graceful drain process for the old cluster.
- Once the graceful drain is complete, the control plane shuts down an old cluster and removes it from the system.
- The upgrade process stores rollback information for the engine in case a regression is detected later, and the fleet needs to be rolled back.
### Upgrade verification process
The upgrade verification process tracks various metrics from old and new engine clusters. Tracked metrics include query latencies and success rates.
The verification process uses a sliding window to compute latency distributions for the queries that ran within verification windows. It detects whether there are any latency regressions caused by the rollout of the new database software version.
When tracked metrics converge within an acceptable margin or error, the verification process returns control to the single-engine upgrade process.
If the error rate for the queries running on the new version of the database software increases, the verification process aborts, signaling the engine upgrade process to rollback.
### Fleet wide upgrade
At the fleet-level, the engine upgrade process updates engines based on the segment - a group of customers at a time, grouped by the risk profile in order of:
- Firebolt Internal
- Preview
- Stable
For a single segment upgrade process is:
- Upgrade running engines in the segment
- Update the default version for new engines in the segment
- Update the version for the stopped engine in the segment
If a regression is detected during the upgrade, rollback procedures are performed promptly to mitigate the impact on customers.
The above process continues until all engines are running using the new version.
## Summary
Firebolt engines provide multi-dimensional elasticity to our customers, allowing them to achieve the desired price-performance without causing downtime for customers.
Learn more about engines, or get started for free with Firebolt now.
For more information about Firebolt Engines, read our whitepaper here.