ON THIS PAGE
Firebolt relies very heavily on caches to deliver low latency query performance. When engines start up, all caches are empty. We call an engine in this state "cold". As engines serve requests, caches warmup and query performance improves. To speed this process up, Firebolt introduced the AUTO_WARMUP feature. This enables engines to remember the state of their caches, and proactively retrieve that data when clusters start.
## Implementation
Auto warmup consists of two components — snapshotting SSD cache state and reloading cache from snapshot.
### Making a Snapshot
Explaining how this works requires looking under the hood of your data on Firebolt. Let's take a simple table with two columns:
CREATE TABLE my_table( id INTEGER, name TEXT) PRIMARY INDEX id;INSERT INTO my_table (id, name)VALUES (1, 'Alice'), (2, 'Bob'), (3, 'Charlie'), (4, 'David'), (5, 'Eve'), (6, 'Frank'), (7, 'Grace'), (8, 'Hannah');The primary unit of storage on Firebolt is the tablet. As data is inserted, it is combined into tablets, and column data within each tablet is generally stored separately to enable fast aggregations and scans. The tablet also contains sparse indices that allow efficient access for queries with selective filters. The above data could for example be laid out as a couple cartoonishly small tablets:
Now let's make some queries to this table:
SELECT MAX(id) FROM my_table;SELECT * FROM my_table WHERE id = 3;To serve these queries, we need to fetch a subset of the data above. We need to fetch all the data for one tablet to serve the SELECT *, and we need to fetch id data for all tablets to serve the SELECT SUM(id). We'd then expect our SSD cache to look something like this:
tablet1/ id nametablet2/ idother_old_tablet/ foo bar...We continuously track when tablets in the cache are used to ensure we handle eviction properly. We can use the data from our evictor to construct a list of recently used tablets and columns on every node in our cluster. We use this data to push a snapshot for our engine to s3:

We continually push an updated snapshot like this to cloud storage while the engine is running. When it shuts down this data will be persisted for up to two weeks. When we then restart that same engine, it will be able to retrieve that snapshot and know which data to fetch.
### Reloading Cache From Snapshot
With the snapshot prepared above, reloading our cache is now fairly simple. We simply fetch the snapshot if one exists, then load the tablets in the snapshot from least to most recently used until one of a few conditions is met.
- We've loaded everything: this is our best-case scenario, and means our cache is fully restored
- We hit our timeout: by default we're willing to spend only 30 minutes loading the snapshot, but this can be adjusted as needed.
- Our SSD cache is filling up: if you switch from a large node to a small node, or storage optimized to compute optimized, there might be less disk cache available. We abort the warmup if we see the SSD cache is filling up to ensure there's plenty of room to cache data for user initiated workloads.
Since everything at Firebolt runs on SQL, we use queries under the hood to fetch this data. We restrict the number of threads on these queries to keep the CPU overhead of the cache load around 10%.
## Applications
What does this feature mean for workloads in practice? Let's look at a few examples.
### Online Upgrade
One place where auto-warmup is extremely helpful is in online engine upgrades. When we upgrade an engine cluster, we create and mirror traffic to a "shadow cluster". Using auto-warmup, shadow clusters can be warmed up much faster, since they proactively fetch a recent snapshot of the main cluster's cache, rather than relying entirely on mirrored requests to greedily warmup.
Let's look at cache on a high traffic engine during our 4.23 release.
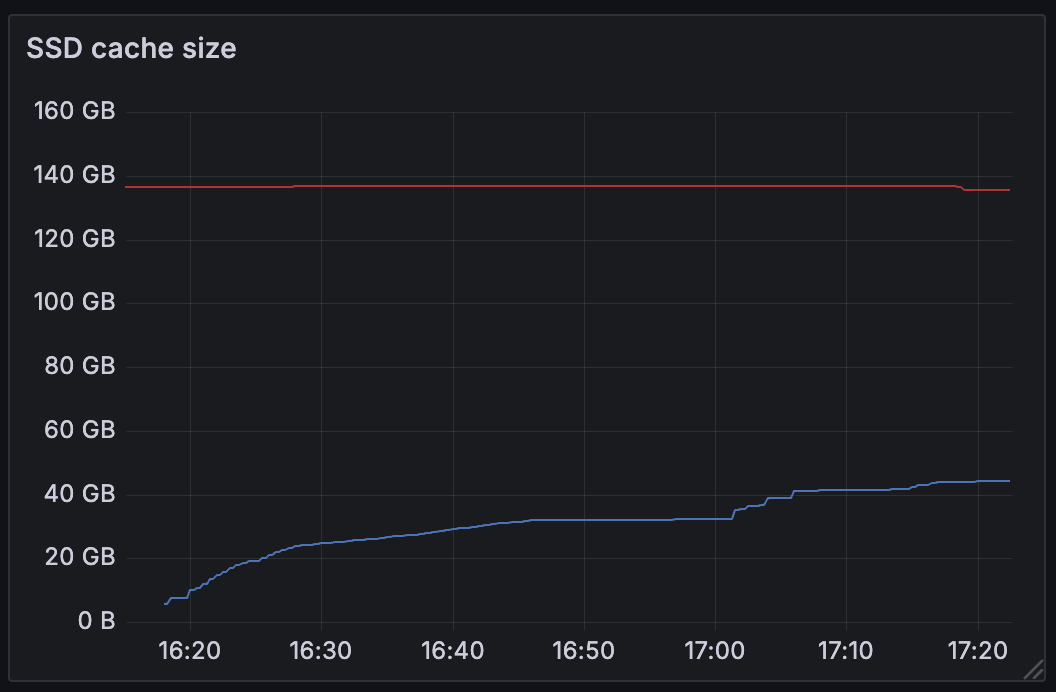
The new node starts up at 16:20 (blue line), and as it receives queries it starts caching data. After an hour, the engine is upgraded, but its cache still hasn't fully converged with the old cluster it's replacing (red line).
Let's compare this to the 4.24 release where auto-warmup was enabled.
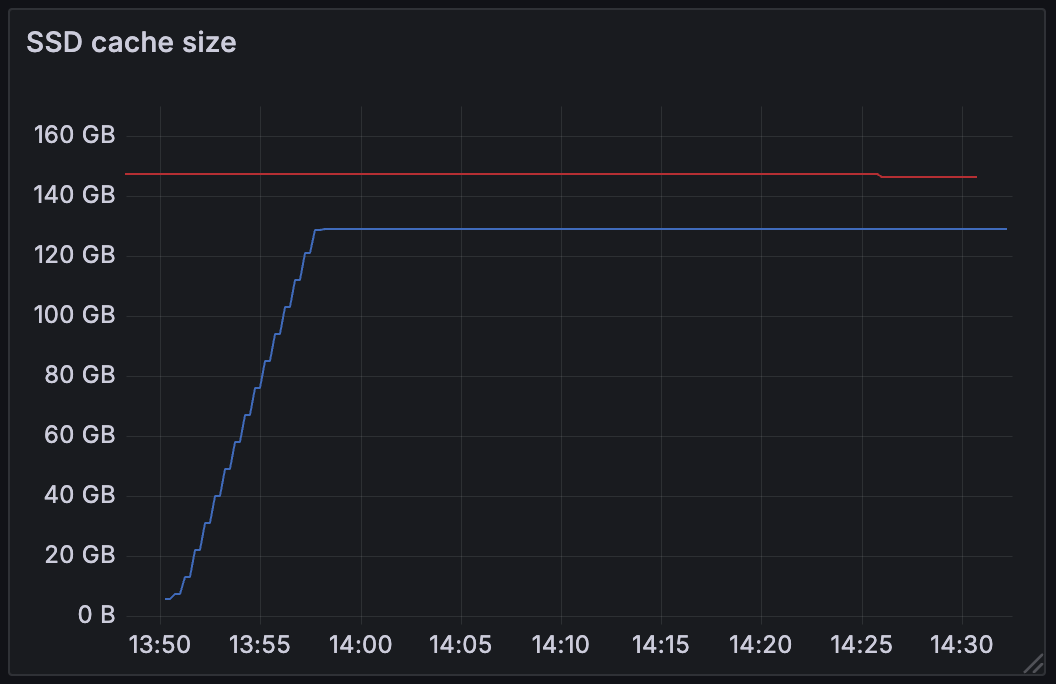
We see the same engine start an upgrade at 13:50. By 13:58, the snapshot is fully loaded, and all queries seen during the duration of the shadow period hit cache.
There are a couple major benefits of this approach:
- The final cache is much warmer. This minimizes the risk of a performance degradation to the customer workload after the upgrade. This also ensures we warmup data that wasn't touched during the upgrade period.
- The upgrade took less time. The first upgrade timed out after an hour, and probably should have been run for even longer to fully warm the cache. The second upgrade finished after just 35 minutes when we saw performance fully converge, and could have been promoted even sooner. Firebolt pays the bill for shadow clusters, so there's no direct cost implication for customers, but this lowers our cost of operating engines, and lets us keep Firebolt affordable.
### User Workloads
Auto-warmup is clearly beneficial in preparing shadows to receive traffic, but what about running this during an intense user workload? To benchmark this, I'm using a modified version of the Firescale benchmark dataset. The benchmark consists of 50 concurrent requests, each picking one of 100k random point read queries against a 1 TiB table, repeated indefinitely.With no auto-warmup, we see a logarithmic decrease in data fetched from s3 throughout the benchmark, as a higher and higher percentage of queries hits cache, but even after 30 minutes, we're sometimes pulling data from s3 as we serve certain queries for the first time.After recording a snapshot from a fully warm engine and trying again with auto-warmup enabled, we can see the difference in the s3 read pattern. The engine is still under a heavy query load and is greedily pulling data to answer those queries, but it is also proactively fetching data it had touched in the previous run. This leads to substantially elevated read traffic initially, but means we eliminate cold reads much faster.
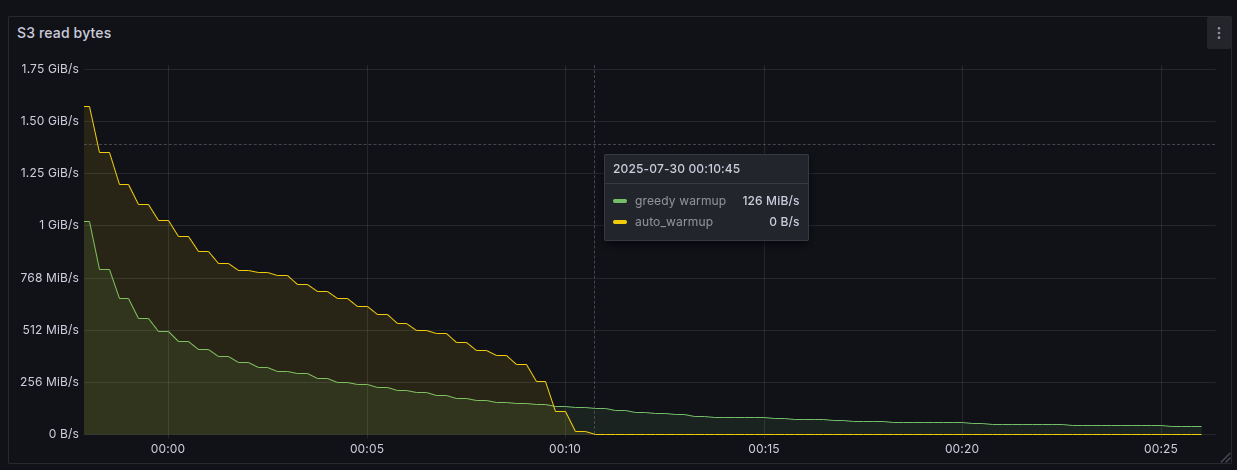
Over the course of the 30 minute benchmark, the engine with greedy warmup averaged 91 QPS and the engine with auto-warmup was able to average 194 QPS as faster reads led to increased throughput.
### Auto-Scaling
When engines auto-scale, new clusters in the engine come up cold. Since the oldest cluster in the engine is maintaining an up-to-date snapshot, the new cluster has a recent snapshot to fetch from when it starts up. Firebolt's load balancer routes to engines based on reported load, so we will already avoid swamping slow clusters, but auto-warmup will much more quickly bring the performance of new nodes to parity with old ones.
## Try It Out!
If you think your workload would benefit from auto-warmup, give it a try. You can enable it on an existing engine by running.
ALTER ENGINE myengine SET AUTO_WARMUP = true;