
Data Lakehouse: Unified Storage for Analytics and AI
Today’s analytics and AI pipelines choke on fragmentation as data sprawls across lakes, warehouses, and silos. This leads to wasted hours moving data between systems just to get a basic model running or a dashboard updated.
A data lakehouse is a means to overcome these challenges as it works by collapsing storage and analytics into one place. By offering one system for storing raw and curated data, running analytics, and training models.
With unified storage, both business intelligence and machine learning teams operate on the same data. A single source of truth that supports high-throughput queries, fine-grained access control, and scalable compute from the same platform.
What is a Data Lakehouse
It combines the low-cost, flexible storage of a data lake with the structure, governance, and performance of a data warehouse. It offers both structured and unstructured data while bringing reliable transactions, tight access control, and fast queries to flexible storage. This setup makes it easier for engineering, analytics, and AI teams to work from a shared foundation without copying data over multiple systems or managing conflicting pipelines. Its traits include:
- Cloud-native storage: Uses low-cost object storage to hold all data types such as raw, semi-structured, and structured.
- Open table formats: Works with Delta Lake, Apache Iceberg, or Hudi for managing large datasets with schema control and versioning.
- Multi-language support: Let's teams query and process data with SQL, Python, R, or Scala.
- Hybrid data processing: Handles both batch jobs and streaming data in the same architecture.
- Simplified stack: Unifies the roles of data lakes and warehouses, cutting down on infrastructure sprawl and operational overhead.
How a Data Lakehouse Works
A data lakehouse builds on cloud object storage, but adds structure through table formats, metadata layers, and compute engines. The result is a unified system that offers analytics, machine learning, and streaming data without moving data between tools. Together, these layers create a platform where raw data can be ingested, transformed, queried, and used for machine learning, all in one place. Here’s how they fit together:
- Data ingestion: Accepts batch, micro-batch, and streaming inputs from pipelines or external sources.
- File storage: Stores data in open formats like Parquet, ORC, or Avro for compatibility and compression.
- Table formats: Uses Delta Lake, Iceberg, or Hudi to add transactional guarantees, schema enforcement, and time travel.
- Compute engines: Query engines like Apache Spark, Trino, and Dremio process data directly from object storage, no staging required.
- Catalogs: Systems like Hive Metastore or Unity Catalog manage table definitions, access control, and schema versions.
- APIs: Expose data through standard interfaces like SQL, REST, JDBC, and notebooks to support BI tools and code-based workflows.
Core Components
A lakehouse architecture is modular by design. It integrates open-source and cloud-native tools across storage, processing, and access layers.

- Object Storage: Stores all data using platforms like Amazon S3, Google Cloud Storage, Azure Blob, MinIO, or HDFS.
- File Formats: Supports Parquet, ORC, Avro, JSON, and CSV. These formats enable compression and compatibility across systems.
- Table Formats: Uses Delta Lake, Apache Iceberg, or Apache Hudi to manage schema evolution, enable transactions, and track data versions.
- Query Engines: Processes queries with engines such as Apache Spark, Trino, Dremio, PrestoDB, Flink, DuckDB, Starburst, or Athena.
- Metadata and Catalogs: Tools like Hive, Unity Catalog, AWS Glue, Nessie, and Amundsen handle table registration, schemas, and permissions.
- Processing Layers: Supports batch jobs (Spark, Dask) and streaming pipelines (Flink, Kafka, Spark Structured Streaming).
- Machine Learning Support: Connects directly to frameworks like TensorFlow, PyTorch, and scikit-learn.
- Notebook and BI Access: Compatible with Jupyter, Zeppelin, Tableau, Looker, Superset, and Power BI.
Architecture Overview
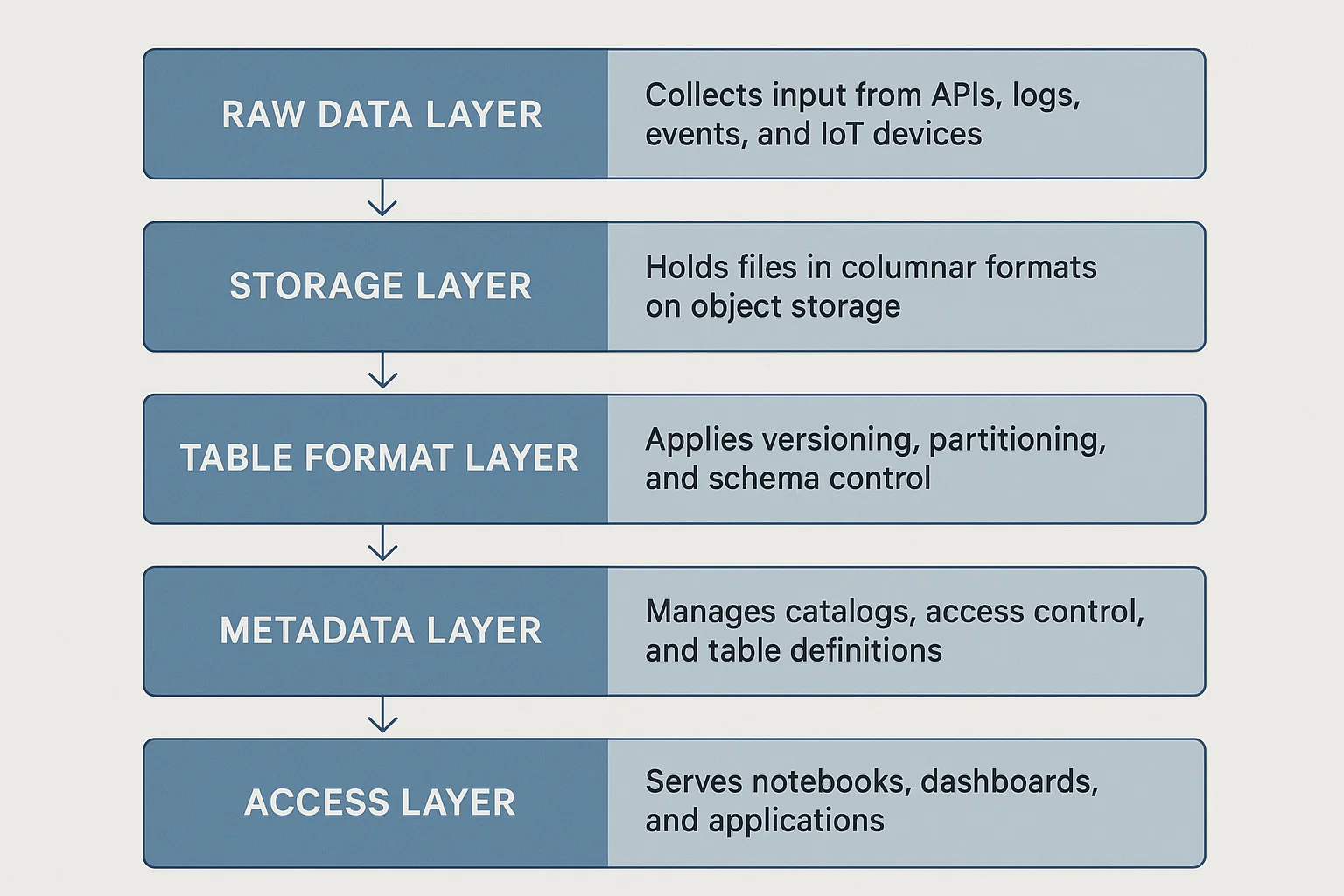
A data lakehouse stacks each layer to deliver a seamless experience across ingestion, storage, processing, and access. Each layer is decoupled but interoperable, so teams can swap tools or scale specific parts as needed.
- Raw Data Layer: Collects input from APIs, logs, events, and IoT devices.
- Storage Layer: Holds files in columnar formats on object storage.
- Table Format Layer: Applies versioning, partitioning, and schema control.
- Metadata Layer: Manages catalogs, access control, and table definitions.
- Compute Layer: Runs SQL, machine learning, ETL, and streaming queries.
- Access Layer: Serves notebooks, dashboards, and applications.
File Formats in a Lakehouse
Lakehouses rely on open file and table formats for flexibility and cross-platform compatibility.
Columnar File Formats:
- Parquet: Default in most lakehouses. Columnar, compressed, supports schema evolution.
- ORC: Similar to Parquet but optimized for Hive and Hadoop-based systems.
- Avro: Row-based format, useful for data interchange and schema evolution.
- JSON: Flexible for semi-structured data, but inefficient for analytics.
- CSV: Human-readable, rarely used for production-scale storage.
Table Formats:
- Delta Lake: Adds ACID transactions, schema enforcement, and time travel to Parquet.
- Apache Iceberg: Provides hidden partitioning, branching, rollback, and scalable metadata.
- Apache Hudi: Tailored for streaming ingestion, upserts, and incremental processing.
Performance Optimization Strategies
Lakehouses improve performance by tightly managing how data is stored, accessed, and processed. These strategies help reduce scan time, improve compute efficiency, and speed up query results.
Partition Pruning
Partitions divide a table into logical segments based on a column like date, region, or customer_id. Partition pruning avoids full table scans by skipping irrelevant partitions.
- Example: A sales table partitioned by year will only scan data from 2024 if that’s the only year requested.
- Impact: Reduces disk I/O and memory use, especially when querying narrow time windows or filtered dimensions.
Column Pruning
Columnar formats like Parquet and ORC store data by column, not row. This allows engines to skip all non-selected columns during query execution.
- Example: If a dashboard query only asks for
total_revenue, the engine ignores columns likecustomer_name,sku, orpromo_code. - Impact: Speeds up reads, reduces memory footprint, and shrinks intermediate data in pipelines.
File Compaction
Write-heavy lakehouses often accumulate many small files. Compaction jobs consolidate these into larger, optimally sized files.
- Example: Delta Lake’s
OPTIMIZEcommand merges files to target 128 MB chunks, the sweet spot for parallel reads in cloud storage. - Impact: Improves scan throughput and reduces cloud object store latency caused by metadata overhead.
Z-Ordering
Z-ordering sorts data across multiple columns by interleaving values into a single ordering. It improves scan locality for multi-column filters.
- Example: Z-ordering a clickstream table by
session_idandevent_timegroups related events close together on disk. - Impact: Query engines can skip large file chunks when users filter on those fields, reducing scan time.
Caching
Caching frequently accessed tables or query results in memory or SSD avoids repeated reads from cold storage.
- Example: Spark’s
persist(StorageLevel.MEMORY_AND_DISK)stores popular datasets across nodes. Trino uses distributed caching for hot partitions. - Impact: Improves response times for dashboards and interactive analysis.
Predicate Pushdown
Engines push filters down to the scan phase instead of applying them after data is loaded.
- Example: A query with
WHERE country = 'CA'only reads blocks where the column statistics indicatecountry = 'CA'might exist. - Impact: Reduces data volume early in the query plan, improving overall efficiency.
Vectorized Execution
Columnar processing engines like Arrow, Spark, and DuckDB use vectorized execution to process data in batches.
- Example: Instead of calling a function 1 million times for each row, the engine processes 1024 values at once using SIMD-friendly operations.
- Impact: Increases CPU throughput and reduces function call overhead.
Metadata Indexing
Table formats like Iceberg and Hudi maintain stats and min/max indexes for files and columns. Query engines use this metadata to avoid scanning irrelevant files.
- Example: A query for
amount > 10_000will skip files where metadata showsmax(amount) < 5_000. - Impact: Reduces unnecessary scans and accelerates query planning.
Auto-Tuning
Some engines adjust execution parameters based on workload patterns, system memory, and concurrency.
- Example: Databricks Photon adapts join strategies and task parallelism based on observed query shapes. Trino adjusts spill thresholds and memory settings on the fly.
- Impact: Optimizes resource use without manual tuning.
Materialized Views
Precomputes the result of expensive aggregations or joins and stores them as static tables for reuse.
- Example: A view that pre-aggregates sales by product and day lets BI tools load reports instantly without reprocessing raw data.
- Impact: Reduces repeated compute and shortens dashboard load times.
Async Writes
Async write paths ingest data in the background while still allowing concurrent reads on previously committed data.
- Example: Apache Hudi’s "write optimized" mode writes data asynchronously to storage while exposing the latest snapshot to readers.
- Impact: Supports high-ingest workloads without blocking analytics or breaking consistency.
Common Use Cases
Lakehouses are versatile enough to power both analytics and AI workloads. They support a broad range of use cases without the need to move data between systems.
- Business Intelligence
Teams build dashboards, KPIs, and custom reports directly from transaction, event, and operational data stored in tables like Delta Lake or Iceberg. SQL engines query fresh data without needing pre-aggregation into separate warehouses.
- Machine Learning
Data scientists train, tune, and deploy models by connecting ML frameworks like TensorFlow or PyTorch directly to the underlying datasets. Feature engineering, training, and inference workflows operate on live production data without copying datasets to new environments.
- Event Analytics
Lakehouses ingest high-throughput event streams such as app interactions, website clickstreams, and IoT sensor logs. These events are processed in real time and stored alongside historical data, enabling queries that span seconds to years without switching systems.
- Marketing Analytics
Campaign data from ad platforms, CRM systems, and internal product usage feeds into the lakehouse for full-funnel attribution tracking. Marketers measure lead conversion rates, lifetime value by acquisition channel, and optimize spend based on unified performance data.
- Customer Segmentation
User behavior, purchase history, geography, and account attributes are combined into dynamic cohorts. Segments are refreshed continuously based on updated data and used to drive targeted messaging, promotions, or personalized product experiences.
- Fraud Detection
Lakehouses allow both real-time flagging of suspicious transactions and historical analysis of patterns. Machine learning models and rule-based systems operate on centralized log, transaction, and event data to detect anomalies and trigger automated responses.
- Product Analytics
Teams track how users interact with application features, identify drop-off points in customer journeys, and monitor adoption rates. Clickstream events and user activity logs feed directly into analysis models without needing external product analytics tools.
- Centralized Governance
Governance layers manage schema evolution, enforce access controls, track data lineage, and audit query activity across raw, intermediate, and curated datasets. Tools like Unity Catalog or AWS Glue catalog are used to secure and document all assets.
- Data Science Access
Data scientists query operational, transactional, and event data directly in notebooks for exploration, hypothesis testing, and model development. Structured access controls and scalable compute resources enable experimentation without bottlenecks.
- Self-Serve Exploration
Lakehouses expose SQL endpoints or BI connectors that allow business users to explore data sets, build reports, and create visualizations independently. Query performance and data permissions are managed centrally to maintain reliability and security.
Data Lake vs Data Warehouse vs Lakehouse
These architectures differ in storage format, schema handling, cost structure, and supported workloads.
Benefits of a Data Lakehouse
Data lakehouses combine the flexibility of data lakes with the performance and governance of data warehouses, offering several key advantages:
- Cost Efficiency: Utilize low-cost cloud object storage, reducing expenses compared to traditional data warehouses.
- Unified Workflows: Support both SQL analytics and machine learning workloads without the need to move data between systems.
- Simplified Architecture: Eliminate the need for multiple data platforms by consolidating storage and processing capabilities.RightData
- Open Standards: Leverage open file and table formats, promoting interoperability and avoiding vendor lock-in.
- Versatile Data Processing: Handle both batch and streaming data, accommodating diverse data ingestion needs.Medium
- Data Versioning: Enable features like time travel and rollback, facilitating data auditing and recovery.
- Cloud Integration: Easily integrate with cloud-native services, enhancing scalability and flexibility.
- Schema Flexibility: Adapt to changing data schemas and pipelines without significant rework.
- Unified Governance: Implement consistent data governance and cataloging across all data assets.
Challenges of a Data Lakehouse
While data lakehouses offer numerous benefits, they also present certain challenges:
- Write Amplification: Some table formats may experience write amplification, impacting performance.
- Performance Tuning: Achieving optimal performance often requires careful tuning and optimization.
- Tooling Maturity: The ecosystem for access control and data lineage is still evolving, potentially leading to gaps in functionality.
- Learning Curve: Managing hybrid workloads can involve a steep learning curve for teams accustomed to traditional systems.
- ACID Compliance Variability: Not all query engines fully support ACID transactions, which may affect data consistency.
- Version Compatibility: Ensuring compatibility across different tools and versions can be challenging.
- Access Control Limitations: Some stacks may lack advanced role-based access control (RBAC) or fine-grained access features.
- Orchestration Requirements: Separate orchestration and pipeline management tools are often necessary, adding complexity.
Cost Considerations
Data lakehouses cut down on storage costs by relying on cloud object storage. But total cost depends on how you manage compute and surrounding tools.
- Storage: Billed based on usage in services like S3, GCS, or Azure Blob, which are typically cheaper than warehouse storage.
- Compute: Costs vary by engine and usage. Trino charges per query execution, while Spark jobs are metered by runtime.
- Caching: Some platforms bill separately for memory usage or SSD-based caching layers.
- Orchestration: Requires third-party tools like Airflow, Prefect, or dbt for managing pipelines and transformations.
- Catalog and Governance: Tools like Unity Catalog or AWS Glue may involve additional charges or licensing.
- Maintenance: Compared to managed warehouses, lakehouses often need more manual configuration and upkeep.
Governance and Compliance
Lakehouses offer strong security and compliance standards when set up across storage, compute, and metadata layers.
- Access Control: Tools like Unity Catalog or Hive Metastore allow catalog- and table-level permissions.
- Column-Level Permissions: Some ecosystems (Ranger, Delta Sharing) are introducing finer access granularity.
- Encryption: Encrypts data at rest and in transit using native cloud settings.
- Auditing: Tracks queries and access events through logs from compute engines like Spark or Trino.
- Lineage: Often added with external tools like Marquez or OpenLineage, or via custom metadata tracking.
- Compliance Readiness: Supports HIPAA, SOC 2, GDPR if properly configured, but not always out-of-the-box.
- Policy Enforcement: Ties into IAM systems, engine policies, and cloud storage permissions to enforce rules.
When to Use a Lakehouse
A lakehouse fits when your workloads span both analytics and machine learning, and you want one platform.
Use a lakehouse when:
- You’re working with structured and unstructured data together.
- You want SQL, notebooks, and model training access from a single dataset.
- You want to stop copying data between lakes and warehouses.
- Your pipelines include batch ETL, real-time streaming, and model training.
- You prefer open table formats over vendor-specific storage.
- You're scaling to terabytes or petabytes and want to keep storage costs low.
- You need flexible schemas to support evolving pipelines and schemas.
Popular Lakehouse Platforms
A range of vendors and open projects support the lakehouse model using modular compute and open table formats:
- Databricks + Delta Lake: Combines Spark-based compute with ACID transactions and ML integrations.
- Apache Iceberg: Backed by Dremio, AWS Athena, Starburst, and Snowflake for scalable table format support.
- Apache Hudi: Optimized for incremental loads and upserts, which are useful for streaming-heavy pipelines.
- AWS Lake Formation: Native AWS service that ties into Glue, S3, and Athena for managed governance and access.
- Google BigLake: Bridges BigQuery with GCS, providing a single query interface over structured and unstructured data.
- Snowflake + Unistore: Expanding toward lakehouse features with support for unstructured and transactional data.
- Dremio: Lakehouse platform built on Apache Arrow and Iceberg with strong SQL support.
- Trino: Query engine that works with Hive Metastore or Nessie catalogs for lakehouse-style analytics.
- Starburst Galaxy: A fully managed Trino platform designed for federated, lakehouse-compatible workloads.
- OpenLakehouse: Community project focused on interoperability across engines, formats, and catalogs.
FAQs
What makes a data lakehouse different from a traditional warehouse?
A lakehouse uses cloud object storage and open file formats, but adds table management and compute layers to support SQL and ML workloads.
Can a lakehouse replace both a lake and a warehouse?
Yes. It can handle structured and unstructured data, support multiple compute engines, and serve use cases across analytics and data science.
Can it handle real-time data?
Yes. Some formats like Hudi and Delta Lake support streaming ingest. Engines like Spark and Flink process updates continuously.
What kind of data works best in a lakehouse?
Lakehouses work well with semi-structured data like JSON, log files, clickstreams, and large-scale structured data in formats like Parquet.
Do lakehouses support transactional consistency?
Yes, depending on the table format. Delta Lake, Apache Iceberg, and Apache Hudi all provide varying levels of ACID guarantees.
How do lakehouses handle schema changes?
Most support schema evolution. You can add or modify columns without rewriting historical data, though compatibility varies by format.
Which tools can query a data lakehouse?
Common engines include Spark, Trino, Dremio, Presto, and Snowflake. BI tools like Tableau and Power BI can connect via JDBC or ODBC.
Is a lakehouse cheaper than a warehouse?
Storage is usually cheaper since it uses object storage. Compute costs depend on engine choice, workload size, and tuning.
What governance tools are available?
You can use AWS Glue, Unity Catalog, Hive Metastore, Apache Ranger, or third-party tools for access control, auditing, and lineage.
Can I use my existing data lake as a lakehouse?
If your data is in Parquet or ORC and stored in object storage, you can add a table format layer like Iceberg or Delta to start querying it like a lakehouse.



