Stream data processing, or simply stream processing, is a Big data technology that goes by different names like real-time streaming analytics and event processing. It involves processing, storing, and analysing a constant data feed from various sources like servers, applications, payment processing networks, and security logs.
## Why is it necessary and what are its uses?
Batch processing of data following a fixed schedule or by fixing a volume threshold (i.e., data was not immediately acted upon generation) is one of the most common processing methods in use. However, this method runs the risk of data becoming stale as data can lose its value when it is not realized at the moment. For example, customer buying patterns may indicate certain preferences specific to a sales event like Black Friday; when this data is processed later it may no longer be of relevance. Thus real-time data processing is essential. Moreover, data is generated more rapidly and data volumes have increased exponentially, so a spontaneous approach as stream processing is of significance today. As data is immediately acted upon in stream data processing, it not only meets the demands of this age but also provides valuable insights instantaneously. For this reason the technology has found uses in almost every industry. Some examples of utilizing stream data processing include real-time inventory management, quick customer/user personalisation (e.g., displaying products or ads similar to those viewed previously, movie and TV show recommendations on streaming platforms), social media feeds, and matching rider to driver on cab-hailing apps (i.e., connecting riders to drivers based on rider specifications, location, and driver availability).
Apart from its usage in predictive analytics, the technology is found valuable in detecting fraud and anomaly. For instance, stream processing enables quick and smooth transactions. So, credit-card processing delays that were typically seen in the traditional fraud detection methods are not an issue in the stream processing method. While a credit-card provider can benefit from the good client/customer experience that stream processing assures, a manufacturer can benefit from massive savings and prevent colossal wastage as the real-time process continuously spots errors in the production line that can be immediately rectified and increase production instead of identifying a whole batch as defective after completing production. Therefore, stream processing's usage extends to Internet of Things (IoT) edge analytics that companies can leverage.
### What are some related challenges?
Stream processing is incomplete without an effective stream processing application because data processing applications help convert raw data into use cases (e.g., location data, fraud detection, and excess inventory). So, companies can either utilize a stream processing software as Apache Kafka that is freely available or build one. Organizations choose to build their own stream processing system depending on the scalability, reliability, and fault tolerance that they desire. However, major challenges lie in building the application according to the company's requirements. For example, designing the application to accommodate a wealth of incoming data that may even be infrequent is a challenge. Another challenge is with handling data that is received from several sources, locations, and in different formats and volumes, as the application should be able to handle such variations and prevent disruptions.
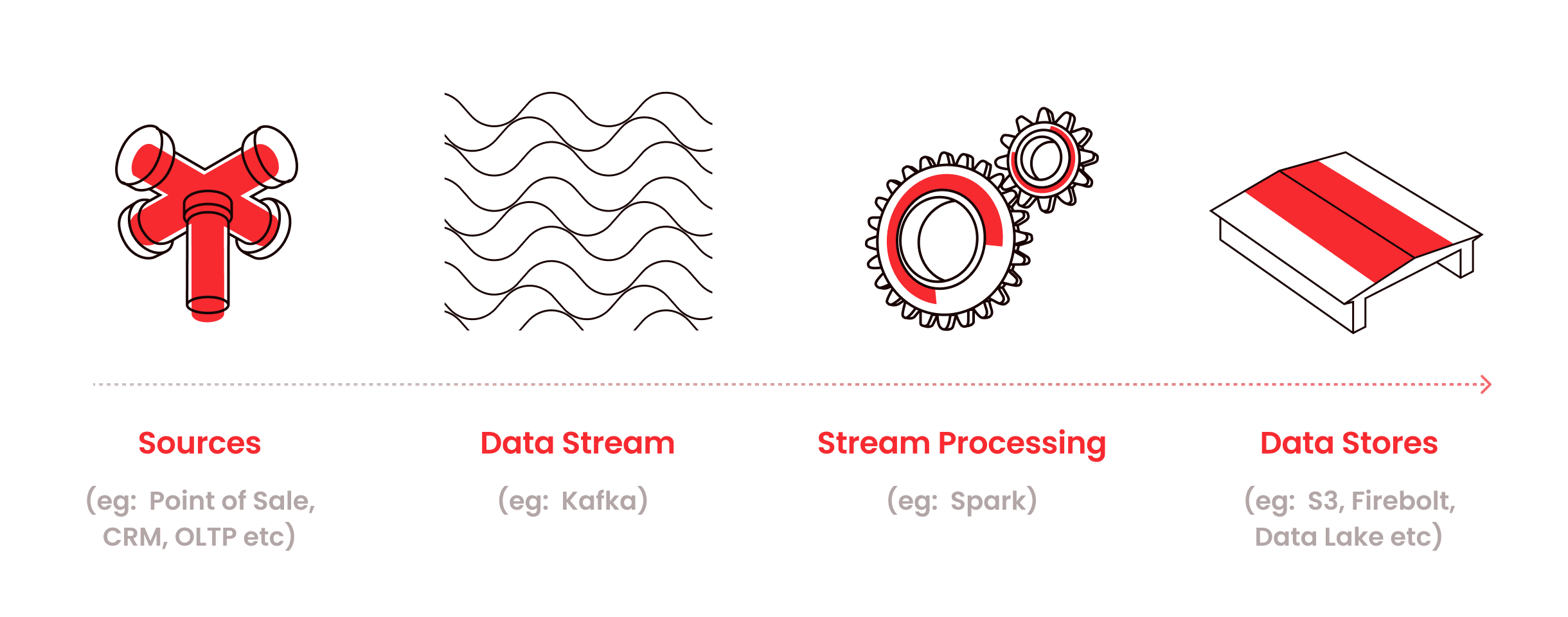
Shown above is an example of a stream data processing architectural pattern that integrates various data sources into different destinations. Once the data is processed by the stream processing application, it can be persisted in data warehouses or data lakes. Cloud based data warehouses and data lakes are commonly used to store streaming data for data analyst and end user access. The ability to scale these backend data stores for capacity and performance is of importance depending on the volume, variety, and velocity of data. Data warehouse solutions such as Redshift, BigQuery, Firebolt, and Snowflake are widely used to address the challenges of scale effectively.