How Engineering teams leverage Firebolt
Self-serve slice-and-dice dashboards at scale
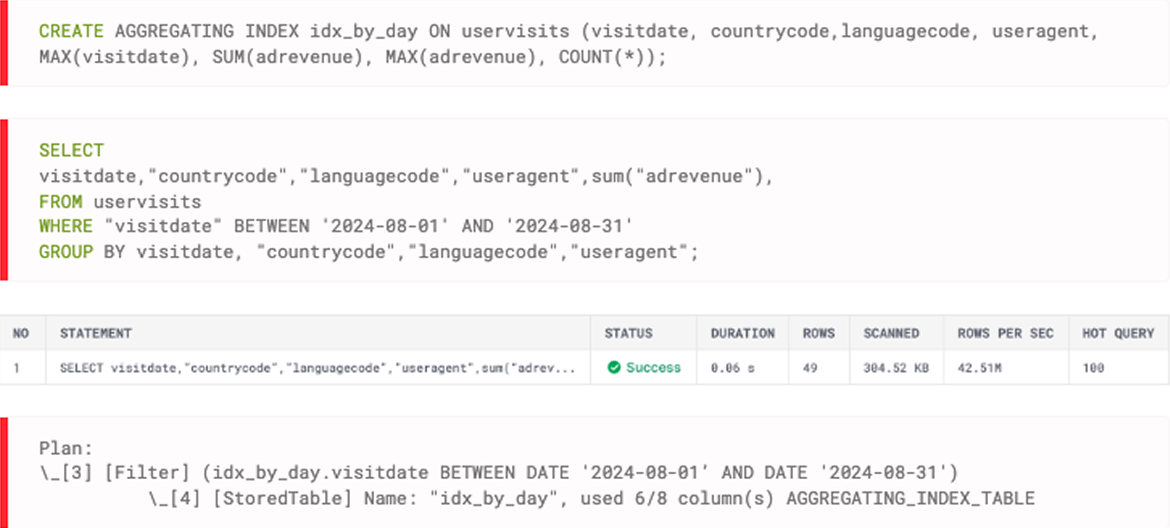
When your end users filter dashboards by their account, region, or time period, they only need their slice of the data. Sparse indexes prune irrelevant data partitions before scan and aggregating indexes pre-compute results for queries.
Multi-cluster scaling to absorb traffic spikes in seconds
Customer-facing dashboards have erratic traffic, shifting from quiet periods to sudden surges. Multi-cluster auto-scaling adds capacity quickly when demand spikes. Separate engines isolate customer dashboards from internal batch jobs.
Real-time data ingestion
Customer analytics dashboards need fresh data. Users expect to see their recent actions reflected within minutes, not hours. Load data continuously via micro-batching from S3, Kafka (via Confluent), or other sources. Aggregating indexes update during ingestion, so dashboards reflect current activity without expensive recomputation at query time.