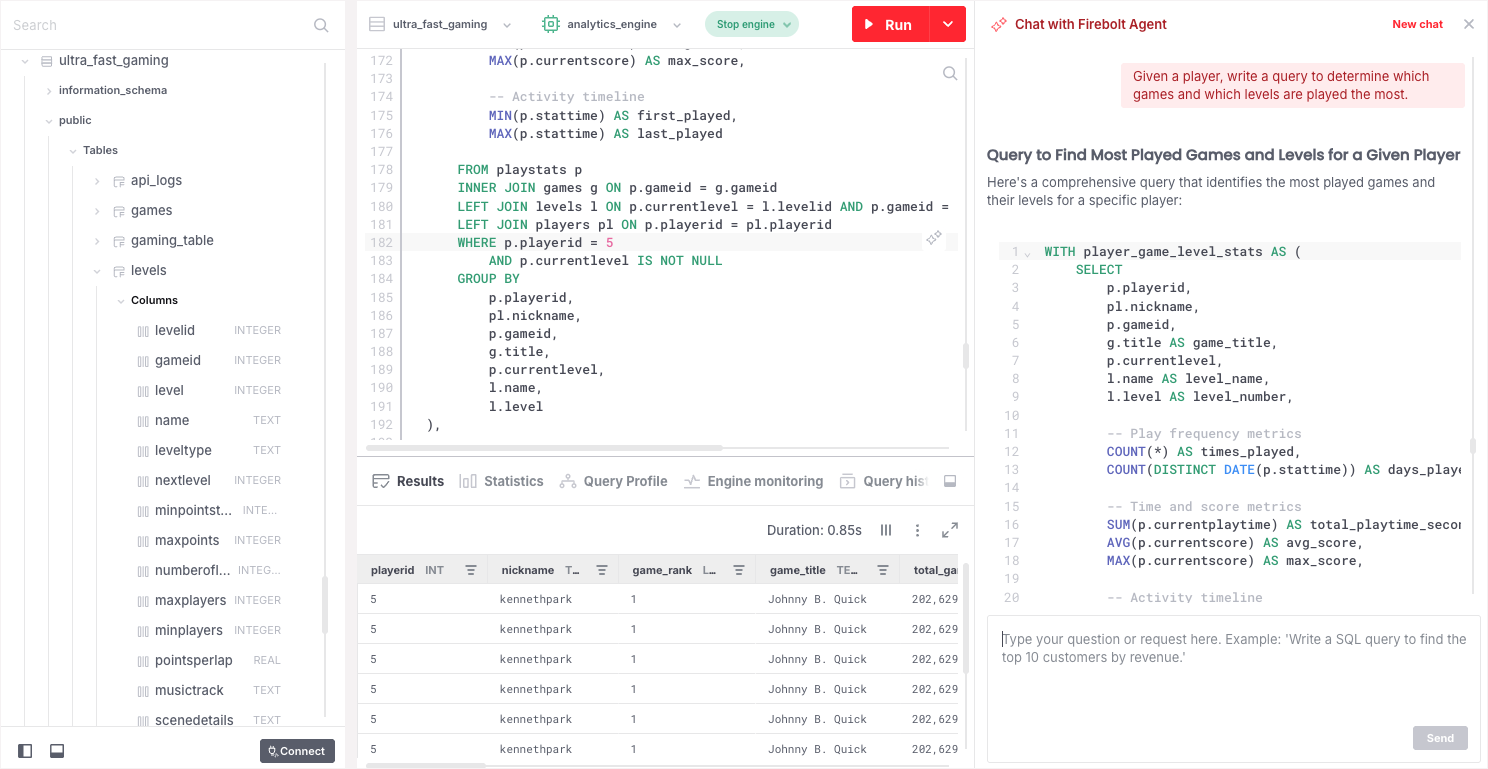


Why data teams choose Firebolt

Millisecond performance
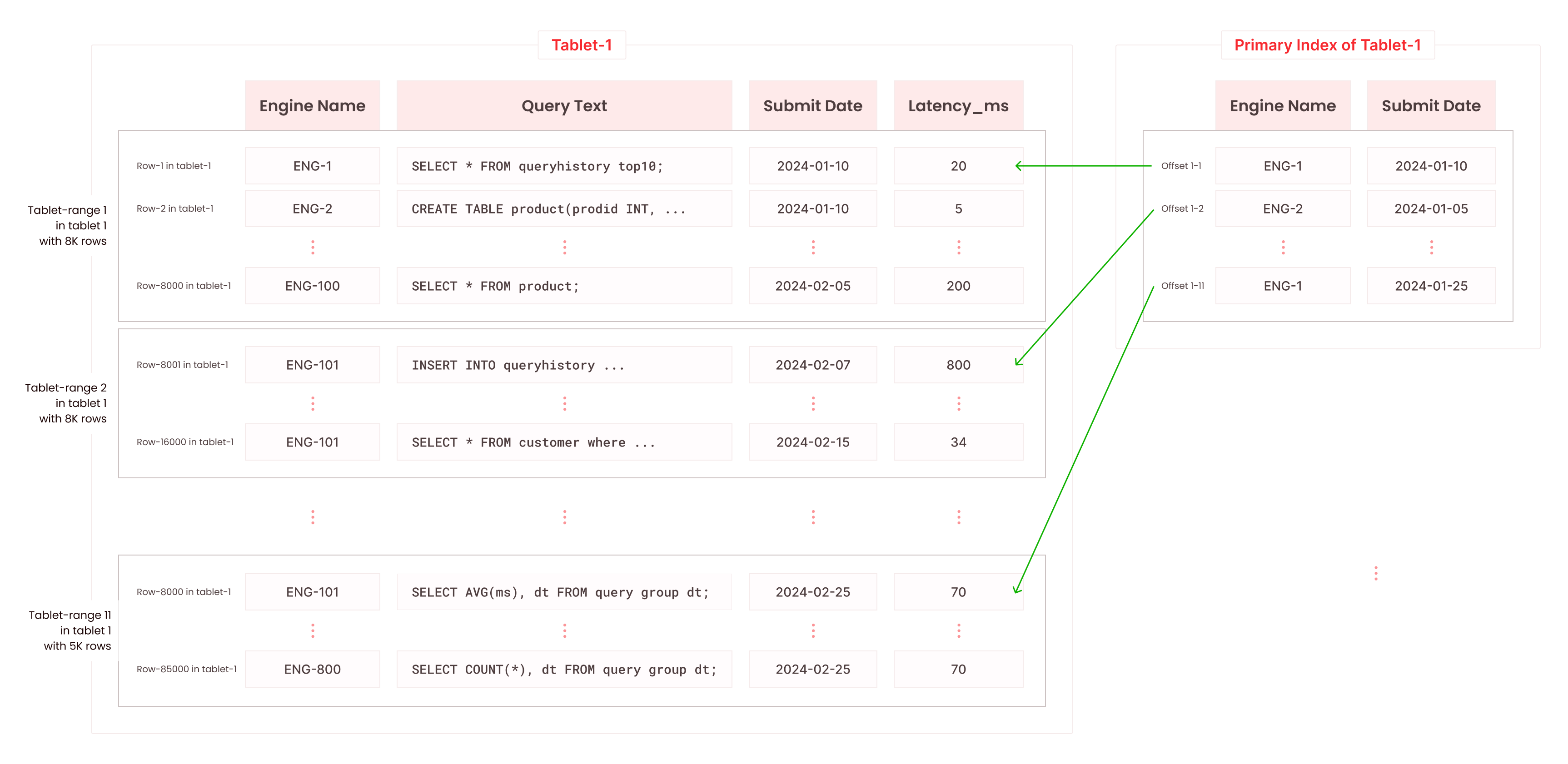
Sparse indexes prune data before scan. Aggregating indexes pre-compute results. Query optimizer adapts to your data. Millisecond response times at TB scale.

Workload isolation with elastic compute
Run dashboards, batch jobs, and AI workloads on separate engines. No resource contention. No query queuing. Engines scale from 1 to 128 nodes and suspend when idle.

Standard Postgres SQL
Standard Postgres syntax. No proprietary dialect. RBAC, schemas, views, CTEs, window functions all work as expected. Define infrastructure in SQL. Version control your entire platform.

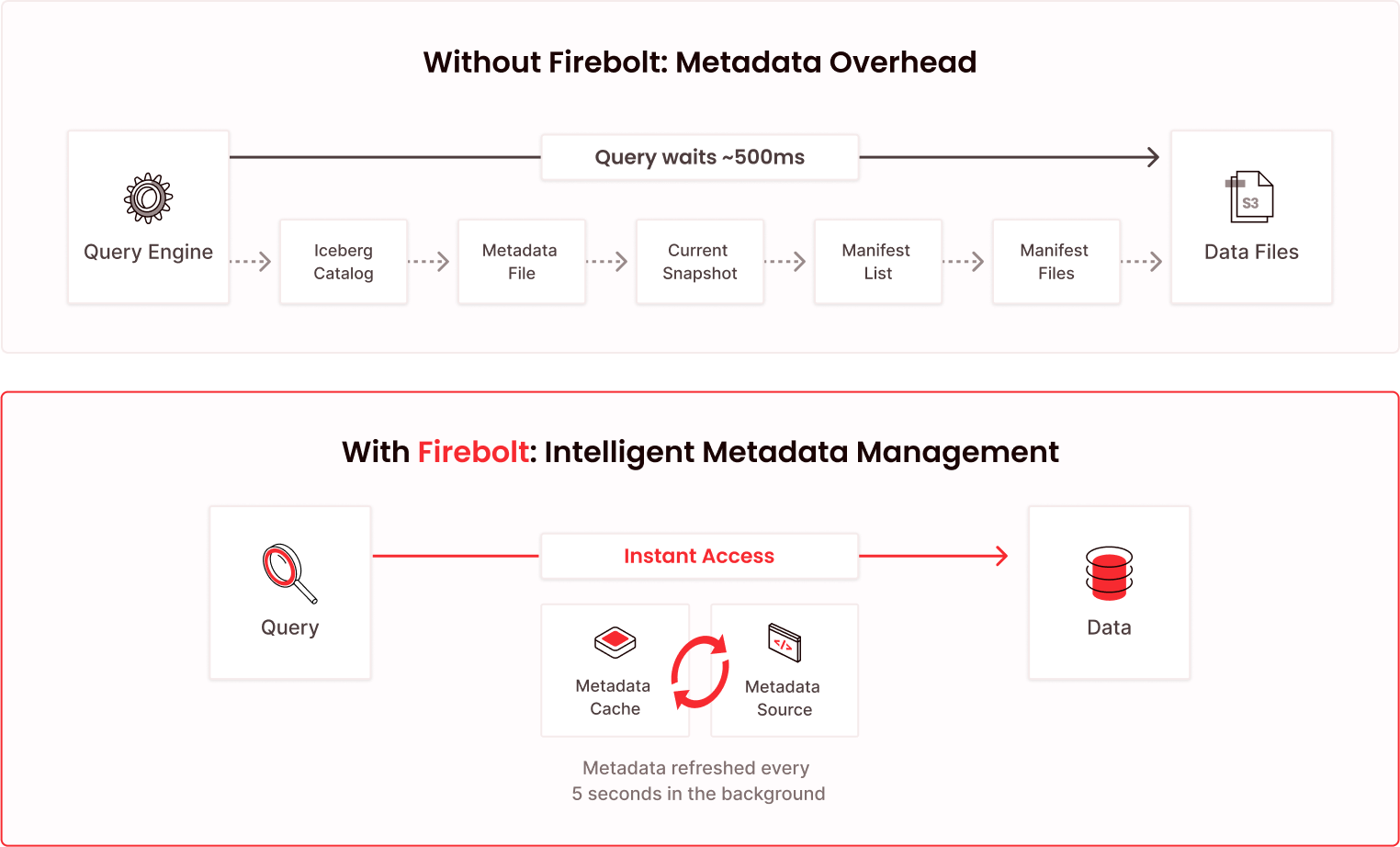
Native Apache Iceberg integration
Read and write Iceberg tables with time travel and schema evolution. Works with AWS Glue, Unity Catalog, and Snowflake Open Catalog. Your data stays in S3 in open formats. No migration. No lock-in

True multi-tenancy
Account-level isolation for each customer. Dedicated databases, engines, and RBAC per tenant. Independent compute scaling. Unified billing with per-account visibility.

ACID guarantees at scale
ACID transactions with snapshot isolation. No partial writes or dirty reads, even during node failures. Transactional DDL: schema changes are atomic and never block queries

Built for AI workloads
Sustain high query throughput for AI agents and LLMs. Thousands of simultaneous queries with millisecond latency. No rate limits. No query queue.

Broad ecosystem integration
Works with your existing data and technology stack. SDKs for Python, Java, Go, Node, and .NET. Integrate with Airflow,Confluent/Kafka, Tableau, Looker, Power BI, and more.







.png)
.png)
.png)
.png)










