ON THIS PAGE
- TL;DR
- Introduction
- Getting the dialect right - postgres compliance
- Why is the dialect so important?
- Protecting users by throwing errors early
- Firebolt's roots in clickhouse
- Modern OLAP Query engines
- A PG compliant runtime - scalar functions
- Keeping users safe - more exceptions
- Postgres compliance - one function at a time
- SQL Test driver
- Test Transpilers
- The Postgres executor
- Overhauling our runtime primitives
- Keeping firebolt fast - function dispatching
- Dispatching for numeric functions
- Dispatching for text functions
- Testing for performance
- Looking ahead - dispatching based on storage statistics
- Conclusion
- References
### TL;DR
This blog post gives a technical deep dive on how the Firebolt team forked off the ClickHouse runtime, and evolved it into a PostgreSQL compliant database system without compromising on performance.
### Introduction
Firebolt is a modern cloud data warehouse for data-intensive applications. This means that Firebolt is capable of both running large-scale ELT queries on terabytes of data, and serving homogeneous low-latency analytics at high concurrency (i.e. hundreds of queries per second).
At the heart of any cloud data warehouse lies the query engine. This is the part of the system that computes the query results: parsing and optimizing a query, scheduling it across the nodes in the cluster, and performing the actual computation such as projections, filters, joins, or aggregations.
As Firebolt is all about performant, cost-efficient analytics, the query engine needs to be as well. Since building a query engine is a massive undertaking, we originally decided to fork our runtime off ClickHouse [1]. ClickHouse is exceptionally fast and proved to be a great foundation in terms of performance [2].
Beyond performance, we also wanted to make sure that we get Firebolt's SQL dialect right. Firebolt is SQL-only, meaning all operations are performed using SQL: provisioning compute resources, setting up network policies, interacting with RBAC, and - of course - ingesting, modifying, and querying data.
For us, getting the dialect right meant aligning with PostgreSQL (PG). The Postgres dialect is widely known and close to ANSI SQL. Almost every data engineer has used PostgreSQL or a Postgres compliant system before. This means that someone trying out Firebolt for the first time can feel right at home and be productive right away. As a database startup, aligning with Postgres also makes ecosystem integration much easier: making tools that work well with Postgres (i.e. all of them) also work with Firebolt becomes much simpler.
While ClickHouse is exceptionally fast, its behavior is very different from that of PostgreSQL. For the Firebolt query processing teams, this meant rebuilding large parts of the system. This was both a huge opportunity, as well as a huge challenge. We needed to re-architect the system while making sure that we remain extremely fast.
This blog post gives an in-depth view on how we evolved Firebolt's OLAP runtime to be PostgreSQL compliant, without sacrificing system performance. We give a deep dive into how modern vectorized database runtimes work, and the engineering challenges we faced moving away from the original ClickHouse runtime to the new PostgreSQL compliant Firebolt runtime. We also give a deep dive on how we bootstrapped our Firebolt SQL testing framework along the way, by both writing and generating Firebolt specific tests, as well as porting tests from other systems using custom automation.
Throughout the blog post, we focus on the changes we've made to scalar functions. Note that this is only a very small part of our larger PostgreSQL compliance story: we've built new aggregate functions, new data types for dates and times, as well as a completely new query optimizer from scratch. We'll talk about that in future posts.
### Getting the dialect right - postgres compliance
Before we dig deep into modern OLAP runtime internals, let's talk a bit more about modern SQL dialects. If you've used different database systems in the past, you've most likely run into this: not all relational SQL databases are made equal.
### Why is the dialect so important?
SQL dialects can be different in many ways. At the surface level, they might differ in how data types or functions are called. When you dig deeper, even functions with the same name might behave differently. Beyond that, advanced language features around type inference, implicit casting, or subquery support (e.g. correlated subqueries) can be completely different.
In principle, there's a standard for all of this: ANSI SQL. The standard has thousands of pages, and we don't know of a system that implements everything that's outlined in the standard. Many systems also have custom dialect extensions that are not standardized. Out of all widely used database systems, PostgreSQL is probably the closest to ANSI SQL.
For Firebolt's SQL dialect, we wanted to stay close to ANSI SQL. However, we also wanted our SQL dialect to be based on the dialect of a widely adopted real-world system. There are two core reasons why this mattered for us:
- Ease of use: by aligning with an existing system, we can make it easy for new users to quickly be productive with Firebolt. While we also support custom dialect extensions, getting your first workload running on Firebolt becomes much easier by aligning with a widely used dialect. People don't have to spend a bunch of time reading your documentation, or getting used to weird idiosyncrasies of your dialect.
- Simplifying ecosystem adoption: nobody uses databases in isolation. People use tools such as Fivetran for ELT, DBT for transformations, MonteCarlo for data observability, and Looker/Tableau for BI. When people adopt a new database system, they expect their existing tools to continue working. Virtually all of these tools generate SQL to interact with the database. By aligning with a widely used existing dialect, building an integration that can generate Firebolt SQL becomes much, much easier.
It's clear that to get the most value from both of the above points, it's not enough to just align with an abstract standard such as ANSI SQL. You need to align with a real system. For us, PostgreSQL was by far the most natural choice: it's widely used, people love it, it works with virtually all ecosystem tools, and it has the plus of being very close to ANSI SQL.
If you look at the wider database space, a lot of other systems have decided to align with PostgreSQL as well: CockroachDB, DuckDB, and Umbra are good examples for this.
### Protecting users by throwing errors early
PostgreSQL is quite strict about functions throwing errors. Functions can throw errors for many reasons. Examples might be overflow checking, or arguments being out of bounds (e.g., trying to take the logarithm of a negative number).
Throwing errors in these cases makes it easier to use the system: instead of returning potentially meaningless results, the query engine lets the user know that they aren't using the functions in a way that's safe. This matters a lot in the case of Postgres: if you use an OLTP system like Postgres to power core parts of your business (e.g., your shopping backend), you don't want to receive wrong results because no overflow checking was performed.
In a similar way as for an OLTP engine, throwing errors early also matters for a cloud data warehouse: people use Firebolt for heavy ELT jobs that ultimately serve their internal or customer-facing analytics. Wrong results propagating through your data pipelines can be hard to catch, and the engine failing silently and propagating wrong/meaningless results makes this much worse.
However, extra safeguards such as overflow checking often come at a cost: there are usually extra checks required to sanitize the arguments and check for errors. If you look at the Postgres implementation of adding two four byte integers for example, you'll find the following code:
If there is no builtin intrinsic for addition with overflow checking, Postgres casts the four byte integers to 8 bytes, and then adds the two four byte values. This can't overflow. It then checks if the result is outside of the four byte integer range. If it is, it returns true indicating that an overflow occurred. Otherwise it casts back to a four byte integer.
Let's write a C++ microbenchmark to figure out how much more expensive this actually is. We implemented a quick benchmark here using QuickBench that compares (1) addition without overflow checking, (2) addition using the manual Postgres overflow checks, and (3) addition with overflow checking using __builtin_add_overflow.
If you look at the code, you'll see that we perform the addition on dense vectors of 1024 rows. This is how modern high-performance OLAP engines work internally, you'll learn more about this in the next sections.
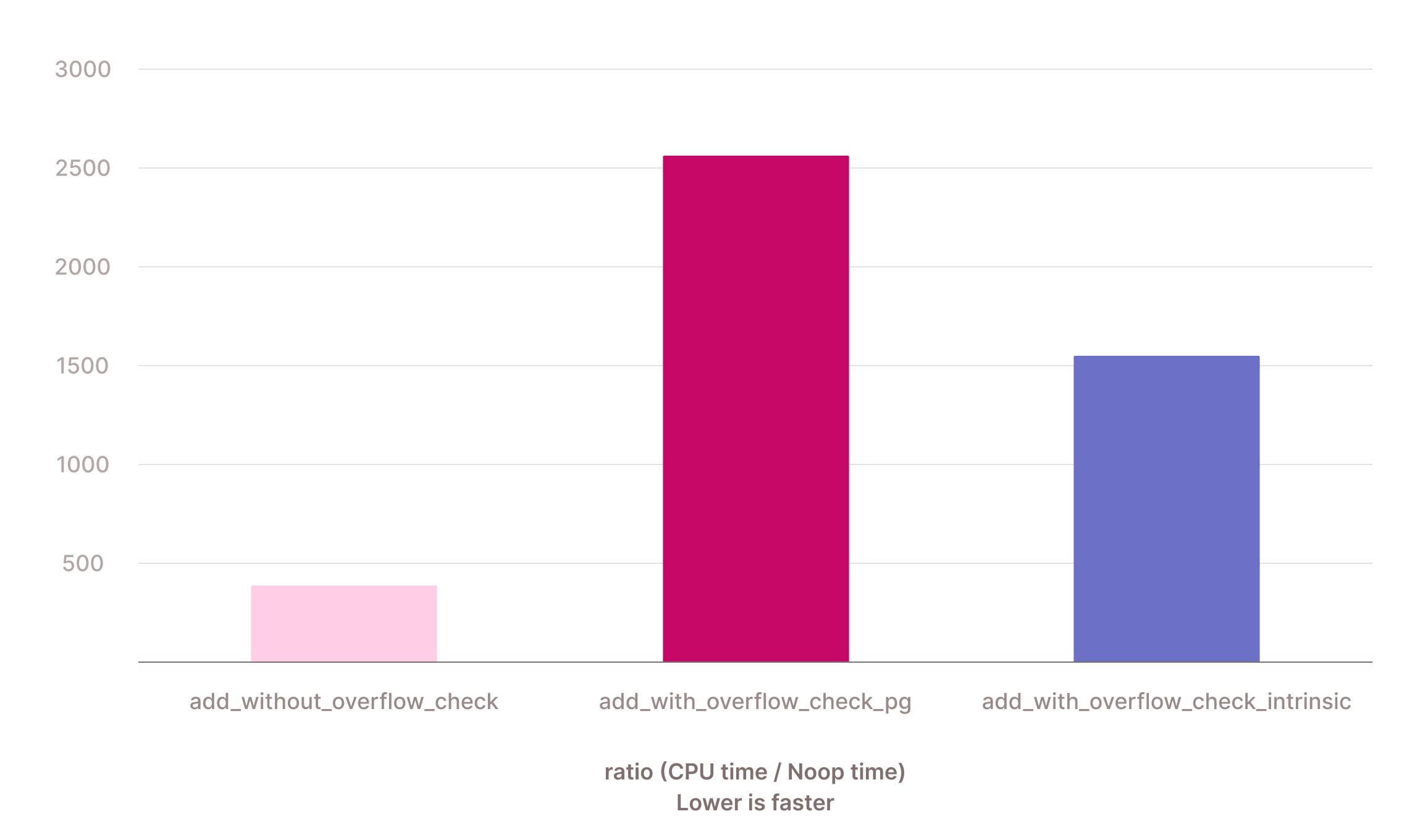
The primitives for addition with overflow checking can most likely be tuned further: we could try to manually vectorize them, be smarter about avoiding overflow checks in some cases, or not throw exceptions in the hot loop. But the naive implementation nicely shows that we're paying a hefty price for the extra safeguards: both using __builtin_add_overflow() and the manual PG-style check is about 4x slower than the version without overflow checking. The microbenchmark also nicely shows why it makes sense to go for the builtin when available: it's about 1,7 times faster than the manual check.
Because of this, avoiding these checks might make sense for some systems: if you're focused on serving already cleaned-up data, optimizing to squeeze out the last bit of performance can be a good choice. This moves more responsibility to the user who needs to use the system in a safe way, but implementing a very fast system becomes easier.
We believe that for a data warehouse, having defensive function implementations that raise clear errors to users is a must. Aligning with Postgres here was not negotiable for us, as we believe that it's the right thing to do for our users. The good news is that it's still possible to build an extremely fast engine with defensive function implementations: for most queries only very little time is spent in scalar functions as other operators such as joins or aggregations are computationally more expensive. Even for a query where a lot of time is spent in the scalar functions, it's possible to tune the function implementations to provide very good performance.
We decided to spend a lot of time performance tuning our runtime to provide a customer experience that's both safe and extremely fast. We'll drill into this in the next sections.
### Firebolt's roots in clickhouse
Alright, with the background on modern SQL dialects behind us, let's start diving into technical details of how we built Firebolt. This section gives an overview of why and how we forked our runtime off ClickHouse.
Building a database system is a daunting task that requires a very large engineering investment. This runs counter to many of the goals you have as a startup: going to market early, finding first design partners and customers, and iterating with them to build a really great product.
To go to market quickly and iterate with real companies, we wanted to fork off an existing open-source system. For us, ClickHouse was the only natural choice. We had three core criteria when it came to the runtime:
- High-performance vectorized engine: we wanted the query engine to be a state-of-the art, low-latency OLAP runtime. If you've never thought about what makes such a runtime special, the next section will tell you more about it.
- Battle-tested: we wanted the runtime to be battle tested and widely used for production use-cases.
- Scale-out engine: we wanted the runtime to have basic support for distributed query processing. As a data warehouse we need to be able to handle ELT queries on massive data volume within a fixed time budget, and scale-out support is a must for this. Nowadays, we've completely rebuilt our distributed query processing layer, but the ClickHouse runtime was great for us in the early days as it allowed for basic support for scale-out processing.
If you want to dig deeper, take a look at our CDMS@VLDB'22 paper on just this topic [1].
At this point, we want to give a huge shoutout to all ClickHouse contributors: ClickHouse has been an exceptional system to innovate upon. It's incredibly fast, layered in a clean way, and elegantly makes use of the building blocks required for modern high-performance OLAP engines such as vectorized processing, a multithreaded and push-based query engine, and efficient columnar storage.
While the rest of the blog post will talk about things we've changed in significant ways, this has only been possible because ClickHouse provided a great architecture that allowed us to make these changes. We made these changes because we believe that it's the right thing to do for the workloads that matter to Firebolt customers, but different choices make sense in the context of different systems and workloads.
By forking off ClickHouse, we managed to achieve our goal of quickly having a functioning, high-performance system. However, we also realized that we had a very long way to go to actually make our query engine Postgres compliant.
Historically, ClickHouse was built for massive-scale serving & reporting workloads at Yandex. Because of this, they've made the conscious choice that they want to optimize their dialect for allowing peak performance for these specific workloads.
As we've seen in the previous section, we decided that this wasn't our desired path for Firebolt's dialect: as we want users to run large data pipelines with complex transformations, raising errors early was extremely important for us. This meant that we had to rebuild large parts of the runtime in order to become Postgres compliant. The next sections will discuss this journey in detail.
### Modern OLAP Query engines
Why are some query engines faster than others? While two systems might speak a similar SQL dialect, they can be built in completely different ways when you take a look "under the hood".
Historically, most systems implemented a row-at-a-time interpreter for relational algebra [3]. This is also called "Volcano"-style query execution. Many OLTP systems such as Postgres are still built that way. In a Volcano engine, individual rows are moved from one operator in the query plan to the next. They flow "upwards" from scan operators through filters, projections, aggregations, etc. Once rows arrive at the root of the query plan they can be returned to the user.
At a technical level, these systems implement relational operators such as filters, aggregations, or joins using a simple getNextRow() interface. When calling that function on a filter for example, the filter repeatedly calls getNextRow() on its child operator until a row matches the filter. This row is then passed to the parent. Your query optimizer builds the relational algebra tree for the query, and the result can be retrieved by calling getNextRow() on the root operator until the tuple stream is exhausted.
For OLTP systems that don't process massive datasets in the context of a single query, such an approach performs well. Other things like the buffer manager or indices are much more important for high performance in these systems. For an OLAP engine that does analytics on terabytes of data however, a row-at-a-time interpreter leads to poor performance: it has bad code locality, lots of virtual function calls, and isn't tailored to modern CPU architectures.
The MonetDB and MonetDB/X100 projects from CWI redefined how to build a high-performance analytical query engine [4, 5]. Instead of implementing a row-based interpreter, MonetDB performs in-memory columnar query execution with specialized primitives. X100 went beyond that by passing batches of around one thousand rows through the query engine. Such query engines are called "vectorized" query engines.
The data flow in vectorized engines is similar to the one in a Volcano engine. Rows also flow "upwards" the query plan from scan operators all the way to the root of the query plan. Compared to the Volcano model where you just pass a single row from one operator to the next however, you now pass a whole batch of rows between them. These rows are usually stored in a columnar layout, meaning that a single column in a batch occupies a dense memory region.
Modern vectorized engines are much more efficient than traditional Volcano engines: the working set fits into the CPU caches, code locality is improved and virtual function calls are amortized over multiple rows. Most importantly however: CPUs love operating on batches of data. The code in the engine is much more friendly towards modern CPU architectures. It can leverage prefetchers, branch predictors, and superscalar pipelined CPUs much more efficiently.
The code in such a query engine looks similar to the microbenchmark we showed earlier. A scalar function for example receives a batch containing a few thousand input rows, and computes the function result for the entire batch:
These primitives are the basic building blocks of your vectorized query engine. You need them for all your supported scalar and aggregate expressions. More complex relational operators such as joins and aggregations should also always operate on batches of tuples. This can be especially beneficial when operating on large hash tables: by working on a batch of rows you can issue lots of independent memory loads and saturate your memory bandwidth.
Most modern OLAP engines implement vectorized query execution. ClickHouse, the system Firebolt forked from, is built in exactly this way. This is one of the core reasons why ClickHouse is so fast. There's a great paper about their engine at this year's VLDB [2]!
Many other modern OLAP systems such as DuckDB [6] (also from CWI, the group where vectorized execution was invented), Snowflake [7], and Databricks' Photon [8] follow this approach.
Note that there is a second approach to build modern high-performance query engines: some systems such as Hyper [9] or Umbra [10] just-in-time (JIT) compile a declarative SQL query into machine code [11]. While this is super cool technology, it doesn't really matter for this blog. In practice, vectorized and compiling engines tend to perform similarly [12].
### A PG compliant runtime - scalar functions
You now know how modern vectorized query engines work: they have simple primitives operating on batches of a few thousand rows, allowing them to efficiently leverage modern CPUs. You also know that Firebolt forked from ClickHouse, which is a modern OLAP engine that implements vectorized execution. In this section, we will dig into how we evolved our runtime to become PostgreSQL compliant.
### Keeping users safe - more exceptions
We mentioned earlier that we decided to align our dialect with PostgreSQL because it's widely used, close to ANSI SQL, and protects the users by throwing errors early. This meant that we had to take the parts of ClickHouse that aren't PostgreSQL compliant, and rewrite them to align with our target dialect.
ClickHouse decided to optimize their dialect for pure performance. In the context of ClickHouse workloads, this makes sense. This means that many functions do not throw exceptions when PostgreSQL does. Let's look at a few examples. You can easily try these out yourself using tools like ClickHouse Fiddle or OneCompiler for Postgres.
All of these examples are quite simple, but imagine subtle conversion errors happening deep inside of an ELT job. This makes debugging hard or – even worse – you might not even notice that things went wrong. This is why we believe that a data warehouse should throw errors in all of the above examples.
## Postgres compliance - one function at a time
This meant we had to carefully evaluate for every function in our dialect whether it's compliant with PostgreSQL. For functions that are not supported by PostgreSQL, life is a bit easier, but we still wanted to make sure that our implementation matches PostgreSQL "in spirit" and raises errors early.
It's hard to come up with all the subtle ways functions might behave differently. As a result, for any function that we added to our SQL dialect, we followed a checklist to ensure that we align with Postgres:
- Port SQL correctness tests from the PostgreSQL test suite
- Port SQL correctness tests from other open-source SQL test collections. In our case we always checked at least DuckDB, Sqlite, MySQL, SparkSQL, and ZetaSQL
- Write custom Firebolt tests, explicitly checking for NULLs, corner cases, etc

This effort ultimately made us completely overhaul the scalar and aggregate functions in the Firebolt runtime. For most functions in our dialect, we either (1) completely reimplemented them, or (2) took the original ClickHouse implementation and changed it significantly to change error handling.
This was a lot of work, and we built some tools to make it easier for us to port tests and ensure that Firebolt really matches Postgres behaviour.
#### SQL Test driver
We have a simple SQL-based test driver that's hooked up in our CI. Using this test driver, you can very easily define SQL tests. You can write arbitrary SQL queries (DDLs, DMLs, DQLs), and then check that the query's result set matches the expected result. Here's an example test that our CTO Mosha wrote that I especially love:
Our SQL tests can run in different environments:
- A "local" mode that mocks away dependencies such as S3/MinIO and our metadata services. This mode allows for extremely fast iteration times when working on the runtime.
- A "remote" mode that can run against a version of "Firebolt light" running on a local developer machine. This makes full use of MinIO and our metadata services. Compared to the local mode, this allows us to test much more of our system: interacting with object storage, SSD caching, and transaction processing.
- A "cloud" mode that runs against a Firebolt engine running on AWS. This also tests our cloud infrastructure, routing layers, and authentication flows.
The "local" and "remote" modes run in the CI on every PR that gets merged to main. We nowadays have more than 100.000 SQL queries stressing every part of our dialect that run on every commit. The "cloud" version of the SQL tests runs nightly and before every release.
### Test Transpilers
While almost all database systems implement text-based SQL tests as the ones mentioned above, many systems use slightly different formats. DuckDB uses a similar format to Sqlite. Here's an example of the DuckDB tests for length:
To make it easy to port tests from other systems, we wrote custom transpilers that take text-based tests from ZetaSQL, DuckDB, etc. and automatically turn them into Firebolt's SQL test format. This made it much easier to quickly cover Firebolt's SQL dialect with tests from other systems.
### The Postgres executor
When porting tests from other systems, or writing our own tests, we wanted to make it easy to ensure that Firebolt actually matches the Postgres behaviour. For this, we wrote an additional execution mode for our SQL tests: the Postgres executor.
This mode uses the Firebolt SQL tests, but doesn't run against Firebolt at all. Instead, it sends the queries to a locally running Postgres server. We can then take the Postgres output and render it in the same way as our text-based format requires.
When adding a function, this makes it super easy to actually ensure that Postgres returns the same results at Firebolt. Of course, this execution mode doesn't help with custom Firebolt dialect extensions such as our array functions.
### Overhauling our runtime primitives
In addition to writing a lot of tools for testing, we also overhauled how we write scalar functions in our C++ runtime. As you can see in the SQL examples above, ClickHouse doesn't raise exceptions for many functions. This leads to some interesting runtime implementation details when handling NULL values.
In the section on "Modern OLAP query Engines" we've seen that vectorized engines such as ClickHouse always operate on batches of rows. These batches are stored in a columnar format. For primitive data types such as integers, the columns are represented as contiguous memory regions (vectors) packing one integer after the next. More complex types such as TEXTs or ARRAYs usually store an additional vector for TEXT/ARRAY lengths.
For columns that can be nullable, vectorized engines usually store which values are NULL in an additional vector. There are different ways to represent these NULLs [13], Firebolt implements a byte mask indicating which indices in a column of a batch are NULL.
Let's understand how the following data would be represented in an in-memory batch:

The five integer values for Id are stored in an integer column that has four bytes for every entry. The balance values are stored in a double column that has eight bytes per entry. Separate one byte null maps store one byte for every value in the source column. If the null map entry is set to one, this indicates that the value is NULL.
Note that for any value that's NULL, there's still an actual value stored in the data column "behind" the NULL mask. In the above example, this value is set to 0 for the two NULLs in the balance column.
Most scalar functions propagate NULLs: an input NULL also results in an output NULL. At first glance, this seems to yield a very simple implementation for vectorized primitives that contain NULLs. For some scalar function_implementation, the primitive can just look as follows:
You take the logical OR of the input NULLs, and call the function implementation on all values. The above code snippet is great from a performance standpoint: working with NULLs does not require any extra branches, just the extremely efficient logical OR of two byte maps. Splitting the primitive into separate for loops for the null map and the function implementation improves performance. This is how ClickHouse implements many of their vectorized primitives. However, this only works if function_implementation does not throw errors.
In the example above, imagine we wanted to run a query such as SELECT log(in_game_balance) as res FROM players. A primitive that looks like the one above is only safe in the context of the ClickHouse log implementation. As the log of 0 returns -inf rather than raising an error, we can safely perform the computation on all nested values. The output block simply looks as follows:
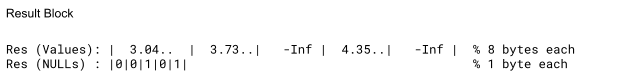
We keep the original NULL map (we only need OR for n-ary functions), and evaluate the logarithm on all nested arguments. The output column now has -inf stored "behind" the NULL values.
This breaks down completely once you start throwing frequent errors in your runtime. We cannot evaluate the function on values that are "behind" NULL, as they might cause errors. In Firebolt, log(0) throws an error, and if our primitives were implemented in the same way, we would throw an error in the above query computing log(balance), even though all balances are positive or NULL.
When implementing the above primitive for a function that can throw errors, you need to be more careful:
This code is less friendly for modern CPUs, as there's a branch (!out_nulls) in the second nested for loop. However, it's safe if function_implementation can throw errors. We could also write the primitive in a single nested for loop. However, the above version is more efficient. Let's write another Microbenchmark on QuickBench to compare the performance. Here, we compare (1) an unsafe primitive that performs addition without overflow checking on all values, irrespective of if they are null, (2) a primitive that changes the control flow to not perform operations behind null values, but still does not perform overflow checking, and (3) a primitive with changed control flow and overflow checking.
Comparing (1) to (2) allows us to see how expensive just the change in control flow is. Comparing (1) to (3) allows us to compare end-to-end performance of the primitives. We run the benchmark with a 10% null ratio.
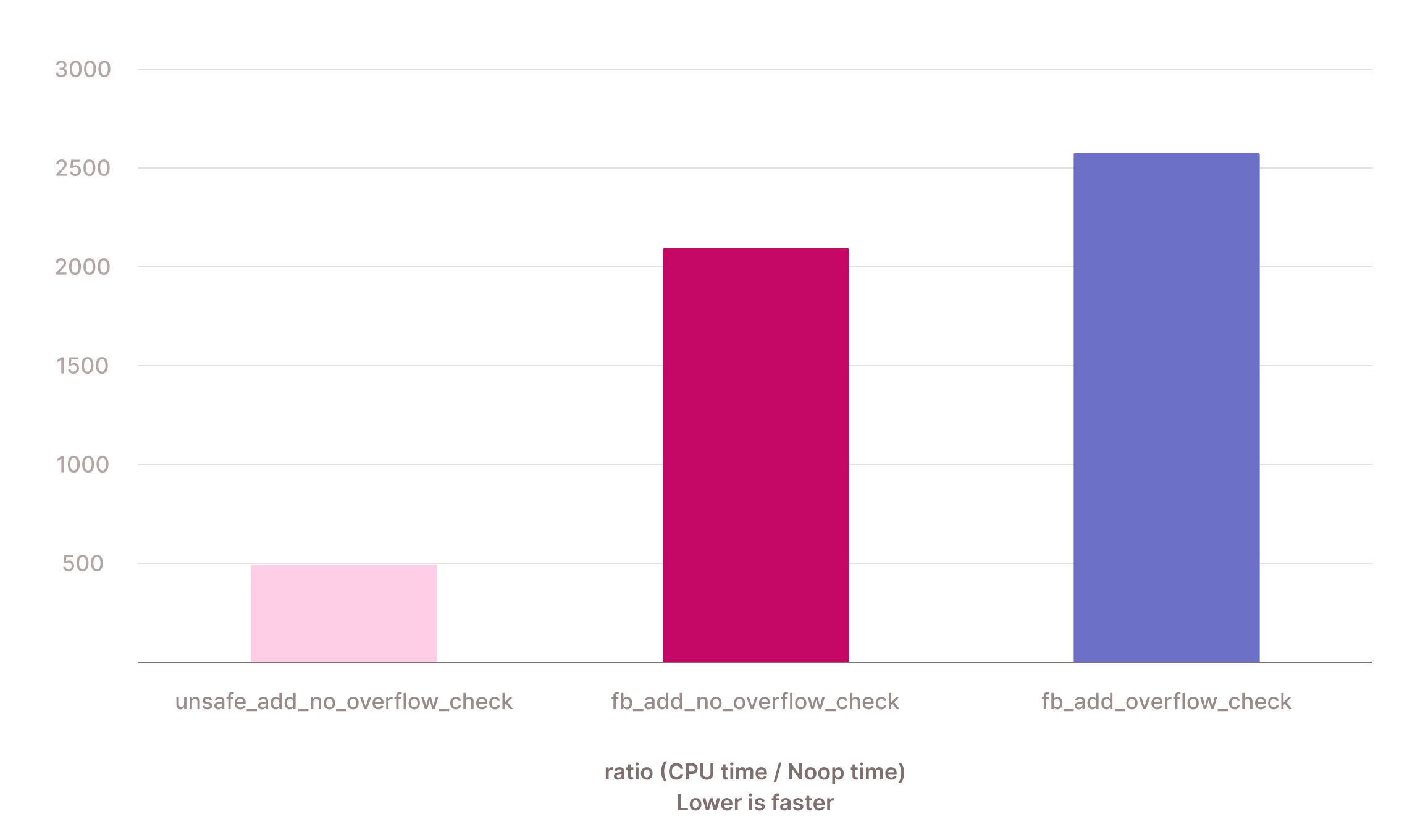
We can see that the change in control flow with the extra branches creates a ~4.3x overhead. Overflow checking causes another 20% slowdown. When you look at the generated assembly, it becomes quite clear why the version without overflow checking is so much faster: it can unroll the loop more effectively and leverage SIMD registers. We've added some comments to show you what is happening where. Note you won't see the null map computation here. That happens in a separate loop before:
Meanwhile, the generated assembly for the safe primitive with overflow checking doesn't do any unrolling:
This shows that when implementing scalar functions that throw exceptions, it's quite easy to end up in a state where the performance of your vectorized primitives suffers.
It might be comfortable to ignore this problem: when executing a query in a system, there's usually a lot more going on: table scans might read data from SSD, you might perform more expensive relational operations such as aggregations, and you need to serialize query results. In many cases, even a 4x slowdown in your addition primitive won't have a large effect on end-to-end query runtimes.
However, the performance difference of the primitives can become noticeable for some query patterns: complex expression trees, selective filters early on in your query, or small scans where data is stored in main-memory. Firebolt is all about high-performance, cost-effective SQL processing. As a result, just living with a 4x slowdown for some of our core primitives was not acceptable. The next section will provide a deep-dive into how we tuned our scalar functions further to make them as fast as possible.
### Keeping firebolt fast - function dispatching
The previous section taught us that it's harder than it might seem to keep a query engine very fast while still throwing exceptions early. The extra argument and result checks in the inner hot loop of the vectorized primitive make it harder to generate very efficient code for modern CPUs. This section shows how we tuned our runtime primitives to still provide the fastest possible performance in as many cases as possible.
#### Dispatching for numeric functions
Usually, people run SQL queries that don't throw exceptions. Let's stick with the example of an ELT job. Throwing exceptions matters a lot when getting an initial version of an ETL query running. But once you have that query running, you want it to run every day/hour/minute and ingest fresh data. Exceptions might still happen here if e.g. your data distribution changed, in this case they are helpful and alert you that you should take a look rather than serving wrong results. But exceptions should be the exception, not the norm.
Can we use this property to actually improve the performance of our system? If we know that it's safe to do addition without overflow checking on a block of data, we can save the cost of doing overflow checks. We can then execute a ClickHouse-style, super efficient primitive, and be sure that we don't miss over- and underflows.
One thing that's great about vectorized engines is that since they operate on at most a few thousand rows at a time, the working set of an expression fits fully into cache. Maybe we can do a first pass over the function, do a cheap check with one-sided error that ensures that the addition can definitely not overflow, and then run addition without overflow checking whenever possible.
We know that adding two four byte integers can definitely not overflow if they are in the range of -1 billion and 1 billion. We can use this property to rewrite our vectorized primitive as follows:
Time for another microbenchmark. We're now comparing (1) the super fast unsafe primitive, (2) the "safe" primitive that always does overflow checking, and (3) the attempted optimization above. There are no rows that overflow, and 10% NULLs.
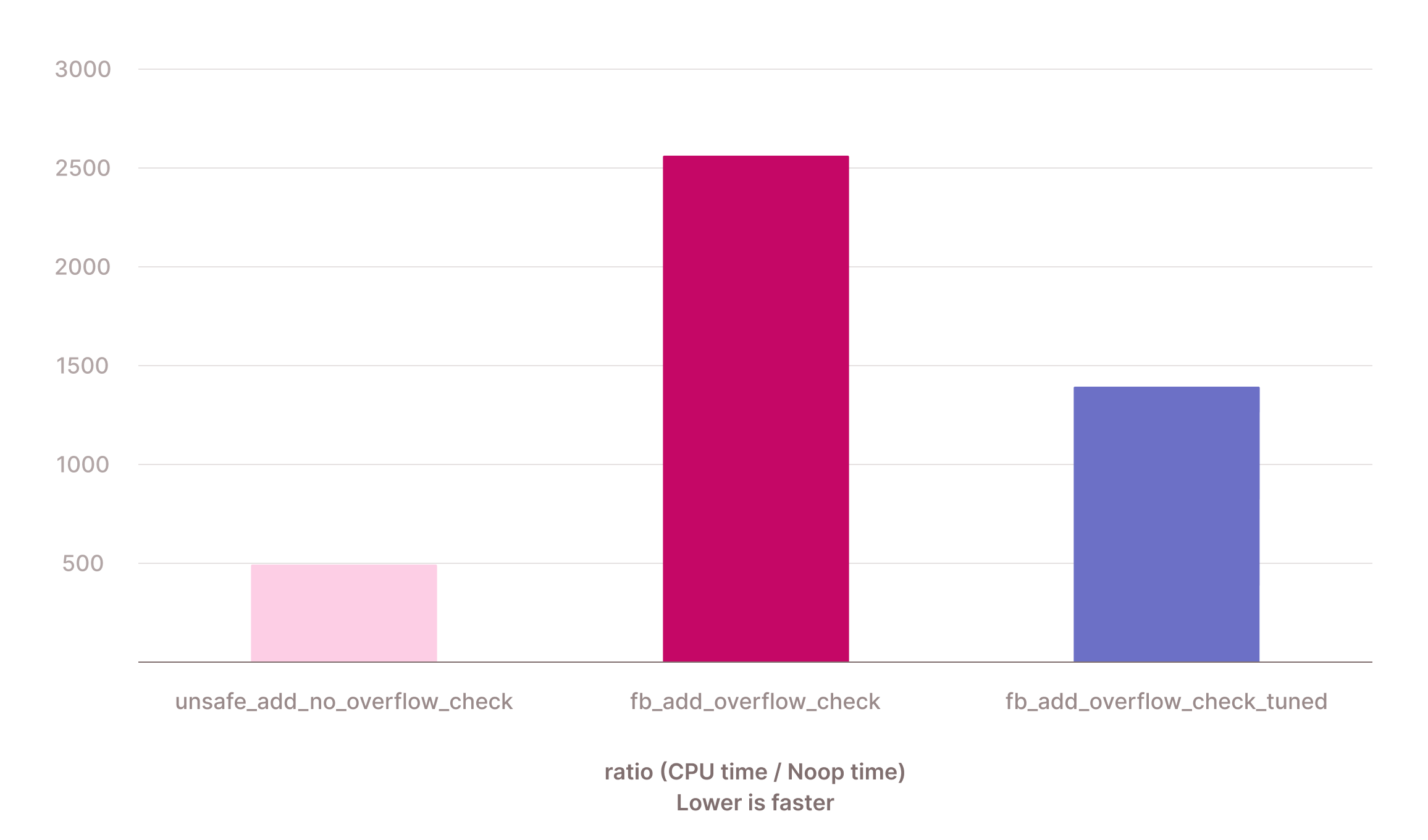
This is a pretty good improvement. We went from being ~5x slower than the original ClickHouse primitive, to being just ~2.7x slower.
What happens if we can't choose the fast specialization? We can also test this in a simple microbenchmark.
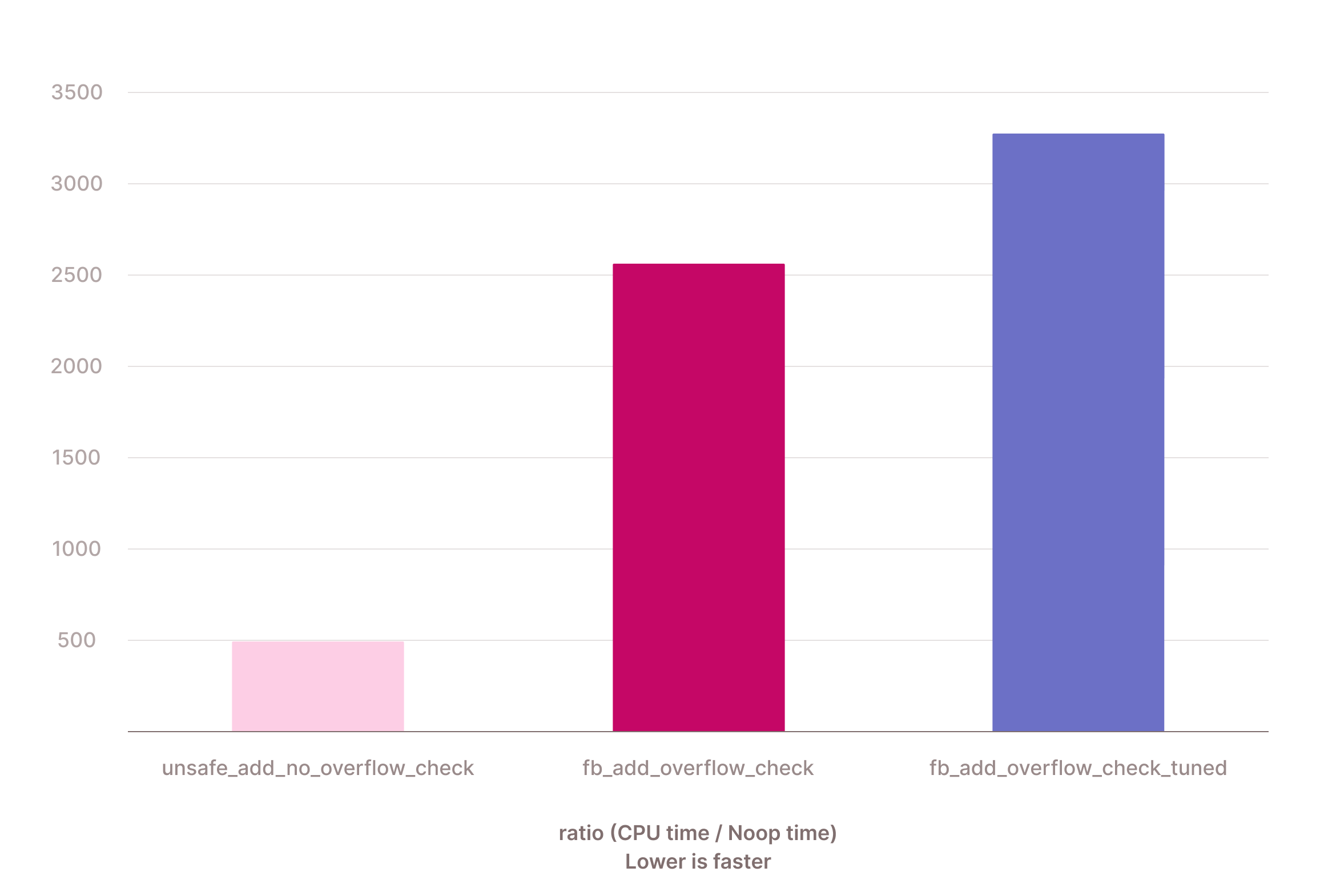
We can see that in those cases, the extra checks cost about 30%. As these cases should be rare, being ~2x faster in the common case seems worth it. There are ways to improve the situation further: if we see that we often choose the specialization with overflow checks, we could at query runtime decide to just always call the safe specialization and not do the extra range checks. We currently don't do that in Firebolt, but plan on doing so in the future.
Addition is one of the cheapest possible functions you can calculate. So getting within ~2.7x of the original primitive is already quite amazing. For more expensive functions, the performance of dispatching like this will become even closer to the performance of the original primitive.
For different functions, you can use different tricks to maximize performance. In many cases, first doing an efficient loop over the arguments to check for invalid values is a good choice. Then you can implement a very efficient loop afterwards that doesn't require nested control flow for argument checks.
#### Dispatching for text functions
Smart dispatching such as above can help a lot for squeezing even more performance out of primitives for numeric functions. However, numeric functions tend to be quite cheap. Text functions in a database system are often much more expensive. Firebolt uses a similar dispatching concept as above to speed up common operations on text columns.
We've seen before how we encode simple columns in our vectorized engine. TEXT columns are stored in two dense memory regions: one containing the text byte sequence, and one containing the offsets of where the individual TEXT values start. There is one more offset than there are TEXT values in the column. The following example column contains three TEXT values: "HELLO, WORLD", "FIREBOLT", and "BLOG POST":

While the text data is variable-sized, the offsets are fixed-size. The offsets act as pointers into the byte sequence and make it easy to work with a string at a specific index.
In Firebolt, TEXT data is always represented as a UTF-8 byte sequence. This means that a single text character can have multiple bytes in the binary representation. The 🔥 emoji for example becomes 0xF09F94A5, which is a four byte code point.
The offsets act as byte indexes and not character indexes in the column. This means if we replace "Firebolt" with the 🔥 emoji the column would be encoded as-follows:

Even though 🔥 is just a single UTF-8 character, the byte-based offsets show that four bytes storage are required.
Most TEXT functions operate on the UTF-8 characters. When calling length(<text>) you care about the number of characters, not the number of bytes in the underlying encoding. This means length('🔥') needs to return one, not four.
Because of that, length can't just subtract the neighboring offsets in the text columns. It actually needs to look at the byte sequence and understand the UTF-8 encoding. It's still quite easy to build an efficient length function that way, but it needs to iterate over the whole byte sequence.
The good news is that for many use-cases, TEXT columns just contain ASCII characters. These are only single-byte code points. If we know that a TEXT column only contains ASCII we can implement length by simply iterating over the offsets.
Luckily, checking whether there are only single-byte code points is incredibly cheap. For many functions, it thus pays off to first check whether there are only such code points, and then dispatch into a more efficient specialization. This is a very similar trick to the one we've used in the section before for numeric functions.
Let's write a microbenchmark for the example of length. We compare (1) a version that checks the actual byte sequence for the number of code points, and (2) a version that checks if all code points are single-byte and in that case uses the offsets to compute the length. We run on ASCII strings of size 10.
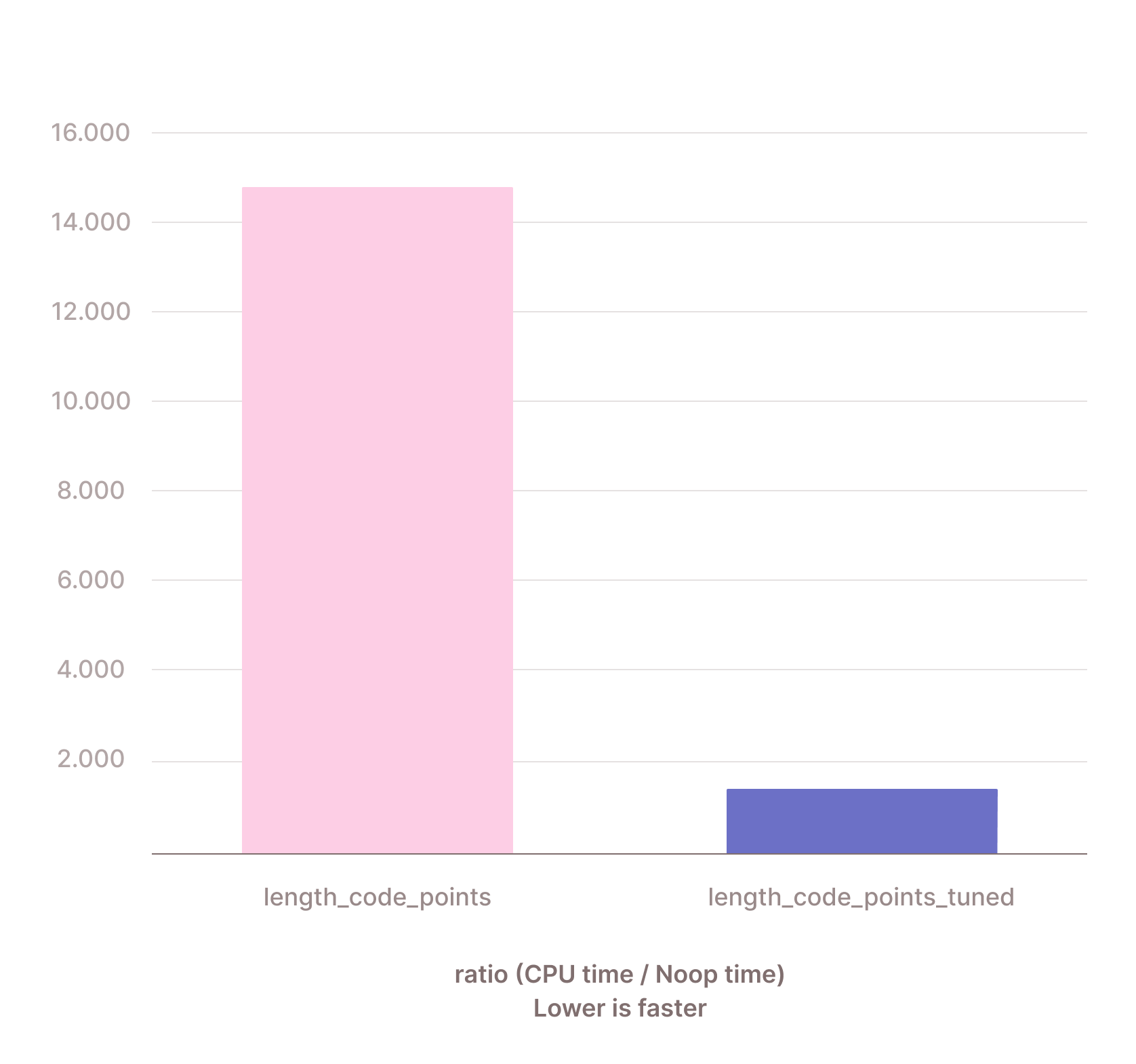
The improvement here is super impressive. By checking whether there are only single-byte UTF-8 characters and then calling into the faster specialization, length() becomes 11x faster than before! When it turns out that there are multi-byte code points, the above numbers also show that the overhead will be <10%. This is because the fast version is an upper bound for the overhead of the code-point checking.
We use this trick for other text functions as well. Further nice examples where this trick can be applied are lpad(<text>, <length>[, <pad>]) and rpad(<text>, <length>[, <pad>]).
Our implementation here is actually even cooler than what we've shown above. We implement these UTF-8 checks as lazily computed column properties. These properties are attached to blocks we pass through our query engine. This means that the primitives don't always recompute whether a text column only has single-byte UTF-8 code points. Instead, the property is computed the first time it is needed and then cached. This reduces the overhead even further.
#### Testing for performance
As you've seen above, microbenchmarks are awesome. They allow you to test a specific code fragment for performance in isolation. Performance tuning isn't easy, and in many cases choices that seem good at first glance can make performance worse.
For all scalar functions we're building at Firebolt, we're writing our own microbenchmarks to validate that they are efficient. In the same way as QuickBench above, we're also using Google's benchmark library. The microbenchmarks need to cover all the different ways the functions might be called: different argument distributions, different NULL ratios.
One thing that really helped us is that after forking, we had all of the original ClickHouse primitives that don't do argument checking. In the microbenchmarks for our Firebolt functions, we thus always had an efficient baseline to quantify whether we're doing well.
#### Looking ahead - dispatching based on storage statistics
The more efficient function dispatching helps us in many cases to make our primitives faster. However, there's usually still some overhead associated to check whether we can call a more efficient specialization.
Our goal is to get the overhead to zero for as many cases as possible. And we believe we can get to zero quite often. For this, we plan on integrating metadata from our storage layer to allow for more efficient dispatching. Firebolt maintains statistics such as tablet-level min/max for every column. This means that when scanning a vectorized block from storage, we can attach the tablet's statistics to the block. We can then use those statistics to directly dispatch into more efficient specializations.
In the example for addition without overflow checking, this would mean that any integer block we read from storage with absolute values smaller than 1 billion can be safely added without overflow checking.
Propagating this "up" the query engine through complex relational operators isn't easy. But as the most expensive expressions are usually evaluated right after a scan, even just having the statistics then can already help a lot. We look forward to talking more about this in a future engineering blog once we've implemented it.
### Conclusion
This blog post gave a deep dive of how we made scalar functions in Firebolt's runtime PostgreSQL compliant. Firebolt decided to align with PostgreSQL's dialect as it's widely used, loved, and provides protections for users by throwing errors early.
To get to market quickly, we decided to fork our runtime off ClickHouse. ClickHouse is an exceptional, modern, vectorized OLAP system. However, our push for Postgres compliance led us to rebuild most scalar functions. We've shown that great testing infrastructure was the backbone of this effort. We have extensive SQL-based tests that can run both on developer machines and on the cloud. And we've invested into test transpilers that make it easy to port tests from open-source systems into our testing environments.
We've seen that making functions that throw errors extremely fast is hard. Sanitizing arguments introduces branches in the hot loops of vectorized primitives, which makes it harder to maximize performance on modern hardware.
To tackle this challenge, we've invested a lot of time into dispatching to efficient implementations of the primitives whenever possible. When we know that addition cannot overflow for example, we call primitives that don't perform overflow checking. When we know that a text only consists of single-byte UTF-8 code points, we call specialized text functions. We're continuing to invest into this by, e.g., enriching our query engine with statistics provided by the storage engine.
This is just a very small glimpse of the work required to build a very fast OLAP query engine that's PostgreSQL compliant. In future blog posts we look forward to diving in depth on how we implemented new PostgreSQL compliant data types, and rebuilt our query optimizer from scratch.
References
[1] Pasumansky, Mosha, and Benjamin Wagner. "Assembling a Query Engine From Spare Parts." CDMS@VLDB. 2022.
[2] Schulze, Robert, eta al. "ClickHouse - Lightning Fast Analytics for Everyone". Proceedings of the VLDB Endowment 17.12 (2024).
[3] Graefe, Goetz. "Volcano - an extensible and parallel query evaluation system." IEEE Transactions on Knowledge and Data Engineering 6.1 (1994): 120-135.
[4] Nes, Stratos Idreos Fabian Groffen Niels, and Stefan Manegold Sjoerd Mullender Martin Kersten. "MonetDB: Two decades of research in column-oriented database architectures." Data Engineering 40 (2012).
[5] Boncz, Peter A., Marcin Zukowski, and Niels Nes. "MonetDB/X100: Hyper-Pipelining Query Execution." CIDR. Vol. 5. 2005.
[6] Raasveldt, Mark, and Hannes Mühleisen. "Duckdb: an embeddable analytical database." Proceedings of the 2019 International Conference on Management of Data. 2019.
[7] Dageville, Benoit, et al. "The snowflake elastic data warehouse." Proceedings of the 2016 International Conference on Management of Data. 2016.
[8] Behm, Alexander, et al. "Photon: A fast query engine for lakehouse systems." Proceedings of the 2022 International Conference on Management of Data. 2022.
[9] Kemper, Alfons, and Thomas Neumann. "HyPer: A hybrid OLTP&OLAP main memory database system based on virtual memory snapshots." 2011 IEEE 27th International Conference on Data Engineering. IEEE, 2011.
[10] Neumann, Thomas, and Michael J. Freitag. "Umbra: A Disk-Based System with In-Memory Performance." CIDR. Vol. 20. 2020.
[11] Neumann, Thomas. "Efficiently compiling efficient query plans for modern hardware." Proceedings of the VLDB Endowment 4.9 (2011): 539-550.
[12] Kersten, Timo, et al. "Everything you always wanted to know about compiled and vectorized queries but were afraid to ask." Proceedings of the VLDB Endowment 11.13 (2018): 2209-2222.
[13] Zeng, Xinyu, et al. "NULLS!: Revisiting Null Representation in Modern Columnar Formats." Proceedings of the 20th International Workshop on Data Management on New Hardware. 2024.