ON THIS PAGE
- Introduction
- The challenge
- Example of real production workload
- SQL API
- Both compliant and fast
- Beyond Postgres
- Planner: Learn from history
- Runtime: Smaller rather than faster
- Distributed execution: Shuffle dilemma
- DML: Automatic incremental index maintenance
- Transaction manager: ACID at no cost
- Conclusion
- References
## Introduction
To understand how we built Firebolt, we need to understand first what we built Firebolt for. We describe Firebolt as a "Cloud Data Warehouse for Data-Intensive Applications". Huh? What does it even mean?
Well, let's start with surveying the landscape of how people do analytics today. Today, we have a generation of modern Cloud Data Warehouses (CDW) such as Snowflake, BigQuery, Redshift, Databricks, etc. They are mature, versatile, battle-tested, and support a wide range of analytic workloads. Today's CDWs can handle BI, reporting, ad-hoc query and exploration, ELT, data science, ML, and, let's not forget AI. They deal with different types of data - structured, semi-structured, even unstructured, geo-spatial, time-series, and, more recently, vector embeddings. CDWs can handle data as batch, micro-batch, and streaming; they connect to a variety of systems - from OLTP to LOB, and, of course, integrate well with Data Lakes and Lakehouses. Amazing!
But there is one thing that the current generation of CDWs struggles with. They are not very fit for supporting data-intensive workloads which require low latency (tens of milliseconds) and high (thousands of) QPS. Workloads which are common in user-facing applications - like mobile apps or Web apps. Today, developers don't dare to connect directly to CDW from an iPhone app and have SQL queries against CDW power interactive experience. This simply won't work, or in rare cases where it might work - would be prohibitively expensive to run at scale. Again, today's CDWs excel at many, many things, but being the backend of interactive user-facing data-intensive applications - is not something they are good at.
So, what do application developers do today? They have to introduce another system for data serving that the application will work against. What system - really depends on the application access pattern. It could be a simple cache; if the application needs key lookup - Redis or Valkey is a good choice; if it needs text search - then Elastic fits the bill. For aggregation queries - Druid, Pinot, or Clickhouse will work. This serving layer could even be MySQL if the data volumes to power the app are small.
There are many specialized systems, each one being very good at what it is designed to do, and solutions employing a dedicated serving system generally work well. However, there are multiple problems with this setup. They all stem from the fact that the data now lives in two systems - one is CDW, where all analytics is done, and another one - the serving system which is exposed to the application. Having two systems is not too bad by itself, as enterprises routinely run dozens (if not more) of systems. However, this approach presents its own challenges:
- Data freshness is compromised, since that data needs to be copied from CDW to the service system.
- Each specialized system has its API, programming model, security model etc. It's not too hard to learn a new API - backend developers will pick it up quickly, but it's a different skill set than doing SQL and database development. And there are many more SQL developers in the world than backend developers.
- These systems all have their preferred data models that they work best with - so data needs to be prepared and molded into that shape. Again, this is not the hardest thing, but yet another set of pipelines to maintain and babysit.
So, we at Firebolt saw an opportunity here: Wouldn't it be wonderful if we could build a Cloud Data Warehouse which can handle these demanding data-intensive applications? The data won't need to leave such CDW, and it will handle both common CDW tasks as well as serve as a backend for workloads requiring low latency and high concurrency. It will have to be a real database system, meaning that it has all the properties expected from DBMS - real SQL (and not "SQL-like"), ACID transactions (and not "eventual consistency"), etc.
So here you have it - that's the Firebolt's vision in one sentence:
Cloud Data Warehouse for Data-Intensive Applications
Or, if you prefer in the poem form:
Low latency
Data intensity
SQL simplicity
Cloud elasticity
Nice vision and nice rhymes, but does the world need Firebolt? Who needs to expose their data to user-facing applications that require low latency and high concurrency? Or to rephrase it - why doesn't every enterprise build such applications on top of their data warehouses? Those are good questions, and we think that if it were easy to build such applications, every business and every enterprise would do it. Today, it's just too hard and too expensive. Well, Firebolt exists to make it easy!
## The challenge
Of course, building a Cloud Data Warehouse for Data Intensive Applications is not easy. The rest of this blog is going to give an insight into how we did it, where every decision was guided by the two simple principles:
- Our system has to be a real analytical DBMS. No compromises.
- The most important workloads are data-intensive applications. Optimize for them; everything else is secondary.
While building analytical DBMS, which works at petabyte scale with low latency and high concurrency, is difficult, there are some things which make it easier. The most important one is that application workloads, unlike ad-hoc queries, are very predictable and contain a limited number of query patterns. We fully take advantage of it by being able to set up indexes which fit the workload, utilize caching of sub-plan results, and automatically adjust query plans based on history. This will be covered in more detail below.
And we also want to be very clear that like always in engineering - building a system means making tradeoffs. In software (like in life), it's not possible to have a system which excels at everything. Getting excellent at A often comes at the expense of B.
And it is, of course, true about Firebolt. In this blog, we will show multiple examples of tradeoffs we took in order to comply with our two guiding principles. Some of these tradeoffs will even look counterintuitive, but, I promise, it will all make sense in the end.
One more question that might be nudging you - is it really practical to build a real user-facing application with SQL database as a backend? Answering queries in tens of milliseconds. Well - why don't we take as an example one of Firebolt customers:
## Example of real production workload
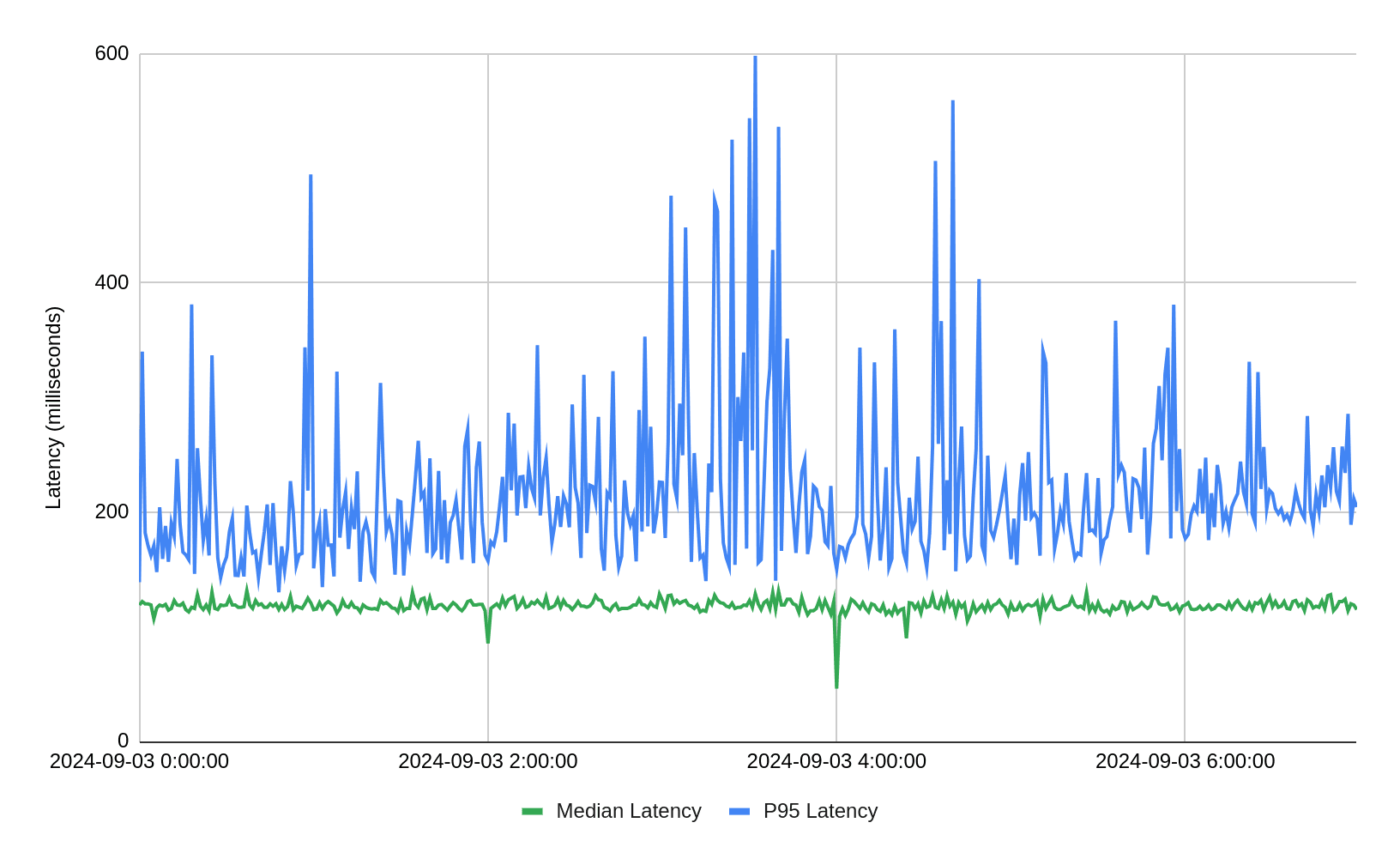
To give an example of such a production workload, let's look at the latency chart of one of Firebolt's customers. It shows median and P95 values for latency in milliseconds - e.g. half the queries finish under 120 ms.
What's more interesting is that these are not simple queries. Let's take a look at a couple of them:
with O as ( select …from Dwhere x IN (...) and y < … and z between … and …union allselect *, …from Mwhere x IN (...) and y < … and z between … and …),C as ( select …, coalesce(sum(case when … then … end), 0) / sum(case when … then … end) - 1 from O group …)select …, sum(...), …from O left join C on …where … between … and …group by …This query has a couple of Common Table Expressions (CTEs), UNION ALL, aggregations and LEFT JOIN. The input tables D and M are tens to hundreds TBs in size (although WHERE clause filters are very selective).
Another query:
SELECT …, COUNT(*), ARRAY_COUNT_GLOBAL(...) / COUNT(*), ARRAY_SUM_GLOBAL(TRANSFORM(x,y -> (y - x), …)) / ARRAY_COUNT_GLOBAL(...), ARRAY_COUNT_GLOBAL(ARRAY_FILTER(x,y -> (x = y), …)) / ARRAY_COUNT_GLOBAL(...), SUM(...) / ARRAY_COUNT_GLOBAL(...),FROM ( SELECT …, ARRAY_FILTER(x,i -> (i = 1), …), FROM ( SELECT …, ARRAY_FILTER(t,p -> (MATCH_ANY(..., ['(?:^|[^\\p{L}\\p{N}])(?i)(word)(?:[^\\p{L}\\p{N}]|$)']), …), FROM D WHERE a = … AND b NOT IN (...) AND … )) GROUP BY …Here, we have aggregations and no JOINs, but a lot of array manipulations, including array aggregations and multiple array lambda functions, as well as the complex regular expression matching function.
These queries power the user-facing application, and with 125 ms median latency, and even P95 around 200+ milliseconds - it provides instantaneous answers to user experience.
## SQL API
We set out to build a database system, and databases speak SQL. In some parallel universe, the term "speak SQL" would've been unambiguous, but in ours - "it is complicated". The SQL language has been accepted by both ANSI and ISO, since 1986, there were nine edition since (SQL-86, SQL-89, SQL-92, SQL:1999, SQL:2003, SQL:2006, SQL:2008, SQL:2011, SQL:2016, and most recently SQL:2023). Despite all this standardization - every single DBMS system has its own unique SQL dialect. Some are more aligned with ANSI SQL, some are less. We had to decide what Firebolt's SQL dialect would look like, and it was the most natural decision for us to align with Postgres's SQL: It is widely used, people love it, it works with virtually all ecosystem tools, and it is also probably the closest one to ANSI SQL. By aligning with Postgres on our SQL dialect, we achieve two goals:
- Ease of use: Postgres is very popular, and many developers used it at some point and are familiar with its SQL dialect. So they would be immediately productive with Firebolt.
- Simplifying ecosystem adoption: The success of the platform depends on the ecosystem around it. And virtually any application working against a database has support for Postgres. And if the SQL that these applications generate for the Postgres connector works without modifications in Firebolt - it becomes easy to have a Firebolt connector.
Choosing to align with the Postgres dialect is a popular choice in the industry - many other systems have done it as well: CockroachDB, DuckDB, and Umbra are good examples for this.
## Both compliant and fast
Choosing to be Postgres compliant does come with certain costs and tradeoffs. Particularly, being compliant, means that SQL functions should have exactly the same behavior, including error handling. Let's take the simplest example of the addition operator: x + y. This operator needs to throw an error if the result of addition overflows the result data type - this is both Postgres behavior and is prescribed by ANSI SQL. In real-world data, such overflows are unlikely, but the code has to be ready for them. It turns out that there is a non-trivial cost for doing such checks in a query engine which uses vectorized execution. So it seemed like we had a hard conflict between our two principles - we want to be a SQL compliant system, but we also don't want to sacrifice even a little bit of performance, as we need to power low latency workloads. Both requirements were equally important to us, so we invested engineering resources to satisfy both of those. Details about how it was done can be found in this blog.
## Beyond Postgres
Postgres compliance is great, but modern data applications need many features beyond what it has to offer. Here, we will discuss one of them - support for arrays. Arrays (alongside with structs) are the two most important building blocks for semi-structured data support. And semi-structured data is ubiquitous in today's data world (thanks to JSON, but also protobufs, Thrift, Parquet, Arrow, and many similar formats). Postgres, being born in the world before that, implements arrays very faithfully to the ANSI SQL specification. Particularly, multidimensional arrays are expected to have same number of elements:
psql=> select '{{1},{2,3}}'::int[][];ERROR: malformed array literal: "{{1},{2,3}}"LINE 1: select '{{1},{2,3}}'::int array; ^DETAIL: Multidimensional arrays must have sub-arrays with matching dimensions.This is ANSI SQL compliant behavior, but it will be breaking pretty much any modern application. So Firebolt adopted a more flexible and relaxed definition for multidimensional arrays:
fb=> select '{{1},{2,3}}'::int[][]; ?column?------------- {{1},{2,3}}Moreover, the ANSI SQL's (and therefore Postgres') way of working with arrays - is to convert them into a relation using a lateral join with UNNEST, and rely on correlated subqueries. This is a very general approach, which allows to do any operation with an array that can be done with a relation using the full power of relational algebra (through SQL, but still). However, it is both cumbersome to program, and query optimizers struggle with efficient query plans on many types of correlated subqueries. Let's take a simple example of filtering out array elements. Suppose we only want to leave even numbers. The Postgres's version of SQL would look the following:
psql=> select a, (select array_agg(e) from unnest(a) e where e % 2 = 0) f from (select array [1,2,3,4,5,6] a) t; a | f---------------+--------- {1,2,3,4,5,6} | {2,4,6}There is a lot going on here for such a simple task - unnest, correlated subquery with aggregation to reconstruct an array after filtering - ouch.
Firebolt recognizes that if arrays are common, then operations with arrays are common too. So Firebolt has a wide arsenal of so-called "array lambda" functions - functions which operate on an array, and one of the arguments is a lambda function telling what operation needs to be performed on each element.
The above query can be rewritten in Firebolt as:
fb=> select a, array_filter(x -> x % 2 = 0, a) f from (select array [1,2,3,4,5,6] a) t; a | f---------------+--------- {1,2,3,4,5,6} | {2,4,6}The x -> x % 2 = 0 is a lambda function here. OK, I know what you are thinking - what about Codd's theorem which establishes an equivalence between relational calculus and first order logic, and aren't we escaping the boundaries of the relational model by introducing lambda functions which look like second order logic? Don't worry - everything's still fine; we are still within the relational model. There is proof, but the margins of this blog are too small for it.
But jokes aside, it is much simpler for the optimizer to reason about scalar functions (even if they operate on arrays and lambdas) than about correlated subqueries and unnest, and it can generate better query plans. Our customers use these a lot - in fact, query 2 from "Example of real production workload" was very lambda functions heavy. As a bonus, array functions (including lambda ones) are allowed in Aggregating Index definition, allowing Firebolt to accelerate them.
## Planner: Learn from history
We already discussed that data application workloads tend to be very homogeneous and repetitive. Since the same query patterns repeat over and over again, it makes a lot of sense to learn from the past execution in order to build better query plans for similar queries in the future. This is what we refer to as History Based Optimization (aka HBO). Many HBO techniques have been proposed - ISOMER [SHMMKT06], STHoles [BCG01], simplified ISOMER [BMHM07] and more recently QuickSel [PZM20].
Of course, Firebolt's planner also uses traditional data statistics, but given our primary focus on predictable and repetitive workloads - we have invested most of our efforts in HBO. The diagram below shows the overall HBO architecture.

To make it work, we first normalize query plans. The goal of normalization is to let queries sharing the same semantics but differing syntactically use the same plan. The normalization process includes but is not limited to
- Remove projections so column pruning and ordering do not matter.
- Join graphs are normalized so join ordering does not matter.
- Filters are sorted so that the order of predicates does not matter. But note that concrete literals do matter.
- Order of window functions applied on the same window frame does not matter.
We fingerprint every subtree in the plan (not just the root), and attach observed execution metrics to it, e.g. row counts. When a new query arrives, the planner tries to match its plan subtrees with the ones learned from the history service and uses historical statistics in the estimation process.
For queries where exact matches are not found, but the plan shape matches (for example, if literal values in the new query are different), we use a variation of QuickSel. A simple example would be the filter operator. Suppose we saw queries with filter predicates x > 10 and x > 50, and learned statistics for them. A new query now comes with x > 20. The QuickSel algorithm allows us to estimate cardinality for this unseen predicate. To do this estimate, QuickSel models relations as k-dimensional spaces, and it models query filters as hyper-rectangles in these spaces, where k is the number of relation attributes.
Learning from history is very important for Firebolt main scenarios, and investing in more sophisticated HBO is a priority for our planner team. The tradeoff here is that focusing on HBO means less investment in more traditional CBO (cost-based optimization) and fancier data statistics.
## Runtime: Smaller rather than faster
We already discussed that our production workloads tend to be very homogeneous, with 10s or 100s of predictable query patterns. Such repetitive workloads can benefit tremendously from reuse / caching. In analytics systems, caching as a concept is ubiquitous: from buffer pools to full result caching to materialized views. Firebolt employs a surprisingly little-used approach: caching subresults of operators. The idea itself is not new, with first publications appearing in the '80s, e.g., [Fin82], [Sel88]. More recent results include [IKNG10], [Nag10], [HBBGN12], [DBCK17], and [RHPV et al. 24]. It also would be appealing to use HBO (history based optimization, discussed above) to help detect common subplans across consecutive queries.
This whole subject is fascinating, and we have a dedicated blog going into depth on it, but here we want to focus on something else.
Since caching is so important for Firebolt's main focus - data-intensive applications - obviously the more we are able to cache, the better. The amount of RAM in the engines is fixed, so the only variable we can control is: using less memory for the cached data structures. And this is exactly how we have designed our runtime data structures. Let us take the one used by our Hash Join implementation as an example. The hash tables built for the Hash Join are great candidates for caching, as there could be many queries with different left sides of the join, but the same right side of the join (e.g., when joining against a dimension or lookup table) - if the right side is chosen as build side of join, it will be the one for which hash table is built.
Usually, designing for performance means coming up with the algorithm with the lowest run time. However, since our priority was to squeeze "more data structures" into the fixed sized memory, for building JOIN hash tables, we did not optimize to have the necessarily fastest algorithm, but aimed for an algorithm which produces smaller hash tables. The details will be described in a dedicated follow-up blog, but the general idea is to make multiple passes over the right side. In particular, we compute statistics so both join keys and values can be packed into as few bytes as possible. Additionally, we even sort by hash values, in order to be able to do delta compression on offsets. Yes, all this may take more time, but if we build this hash table once and use it many many many times, and it takes less memory, there is less of a chance for it to be evicted - i.e., it is worth it!

## Distributed execution: Shuffle dilemma
Firebolt supports multiple dimensions for scaling the processing power of a cluster. One is scale up, where the user simply selects a more powerful node type. However, changes in node type are somewhat coarse grained. If more precise control over sizing is needed, or if there is a need to have more processing power than what a single node can offer - there is a scale out dimension. With scale out, the user can increase the number of nodes in the cluster (and, of course, can also scale up or down the node types within that cluster). Logical query plans for single node and multi-node clusters are the same, but physical plans are different, as multi-node clusters need to add dedicated operators for data exchange between nodes. This data-exchange operator is called Shuffle.
Here is an example query, computing a join and an aggregation:
SELECT r.c, SUM(s.d)FROM r JOIN sON r.a = s.bGROUP BY r.cThe logical query plans are the same for both a single-node and a multi-node cluster:
[1] [Aggregate] GroupBy: ["c"] Aggregates: [sum("d")] \_[2] [Projection] "c", "d" \_[3] [Join] Mode: Inner [("a" = "b")] \_[4] [StoredTable] Name: "r", used 2/4 column(s): "a", "c" \_[5] [StoredTable] Name: "s", used 2/4 column(s): "b", "d"The physical plan for a single-node cluster can execute the entire query in a single stage:
\_[1] [Projection] ref_0, ref_1 \_[2] [Aggregate] GroupBy: ["c"] Aggregates: [sum("d")] \_[3] [Projection] "c", "d" \_[4] [Join] Mode: Inner [("a" = "b")] \_[5] [StoredTable] Name: "r", used 2/4 column(s): "a", "c" \_[6] [StoredTable] Name: "s", used 2/4 column(s): "b", "d"In contrast, the physical plan for a multi-node cluster splits query execution into multiple stages which are connected by shuffle operators:
[1] [AggregateMerge] GroupBy: ["c"] Aggregates: [summerge("d")] \_[2] [Shuffle] Hash by ["c"] \_[3] [AggregateState partial] GroupBy: ["c"] Aggregates: [sum("d")] \_[4] [Projection] "c", "d" \_[5] [Join] Mode: Inner [("a" = "b")] \_[6] [Shuffle] Hash by ["a"] \_[7] [StoredTable] Name: "r", used 2/4 column(s): "a", "c" \_[8] [Shuffle] Hash by ["b"] \_[9] [StoredTable] Name: "s", used 2/4 column(s): "b", "d"The Shuffle operator is the fundamental building block for distributed query processing, and there are many possible designs for it - e.g. [HBEAM18], [SAJHJ19], [MYC20], having different strengths and tradeoffs. Usual considerations are how to make shuffle very scalable and resilient to failures. This makes sense in the context of huge batch jobs, which process petabytes, use hundreds or thousands of machines, and run for hours. These, however, are not the main scenarios for Firebolt - we are focused on data-intensive applications, which need to process queries at low latency. So, we made different tradeoffs - instead of prioritizing scalability and resilience, we prioritized latency and network utilization.
One example of where this tradeoff affects design is - whether shuffle should be pipelined and streaming across stages, overlapping their execution, or whether it should be checkpointing state. The benefit of checkpointing state is that in case of failure, execution can restart from the latest known checkpoint. The drawback is that such checkpoints introduce additional pipeline breakers, and also require additional disk or network I/O to actually write the checkpoints. Since Firebolt optimizes for fast queries, we were less worried about the possibility of entire node failure in the middle of query execution, and therefore chose a pipelined and streaming shuffle. In the unlikely event of node failure during query execution, we can simply restart the respective query from the beginning (with mechanisms in place to preserve idempotence of such restarts, i.e. we would never have INSERT adding same data twice). Note, that our shuffle is resilient against transient failures such as network connection drops.
By being able to overlap different stages of distributed execution, we achieve much lower query latencies, since we can usually hide network I/O in one stage behind processing work in another stage. Again, this strategy works very well for user facing low latency queries, and is not optimal for long running ELT batch jobs - but user facing low latency queries are what Firebolt optimizes for.
When pipelining different operators, it is important not to make writing and reading to shuffle a bottleneck, or the entire pipeline will stall on it. Since most SQL operators are CPU or memory bound, we also needed to make sure that shuffle doesn't use too much CPU or memory while trying to utilize all available network bandwidth. We were able to achieve this by doing all network I/O fully asynchronously using the io_uring kernel interface. But it turns out that even with io_uring, it is not trivial to saturate network bandwidth, when AWS gives you up to 200 Gbit/second. For example, AWS imposes limits on a single TCP connection flow, throttling it at 5-10 Gbit/second, so in order to get higher throughput, we are using dozens of TCP connections between each pair of nodes. Of course, since we are no longer using single TCP connection, we needed to build flow control to maintain ordering of packets over multiple TCP connections. The shuffle code became more complex, but we were able to get very close to full network bandwidth - so for us this tradeoff was worthy.
Another consideration is that 200 Gbit/second is getting close to the memory bandwidth, so we had to be very careful not to do extra copies of data in kernel- or user-space. Finally, shuffle flow control has to include backpressure mechanism to prevent excessive buffering of data on either sender or receiver side.

## DML: Automatic incremental index maintenance
The classic definition of Data Warehouse was given by Bill Inmon in his "Building Data Warehouse" book [Inmon02]
"A data warehouse is a subject-oriented, integrated, nonvolatile, and time-variant collection of data in support of management's decisions." [Inmon]
The book goes on to explain that "nonvolatile" means that data is loaded into Data Warehouse, but not updated, keeping the history of changes. So one would think that in the perfect world, the only DML that Data Warehouse needs is INSERT. OK, and maybe some simple form of DELETE to remove outdated data. But certainly not UPDATE, right ? Well, our world is not perfect, and there are many use cases that require doing mutations in Data Warehouse. Upstream systems need to issue corrections, laws such as GDPR and "Right to be forgotten" require deleting individual records, and sometimes people get carried away and build applications which treat Data Warehouse more like Operational Data Store (ODS) or even a system of record.
Well, we are meeting our customers where they are - if they need UPDATE/DELETEs - we got them. And just like everything else in Firebolt, we always look at these SQL statements in the context of data-intensive applications. For one, it means that these statements themselves should be fast, especially if they update a small number of records. The technique for doing such small deletes is well known - soft deletes, i.e. keeping an auxiliary data structure which remembers which rows were deleted, it is sometimes called deletion vector, and apply it during reads. Firebolt uses Roaring Bitmaps as deletion vector implementation. Roaring Bitmaps is very compressible, yet fast to access data structure.
Below is an example of production workload in Firebolt, where application issues DELETE statements, each deleting a single value from a big table. The charts below show QPS of about 6 per second, and average latency for these deletes is 140 milliseconds (which includes uploading deletion vectors to S3 for durability).
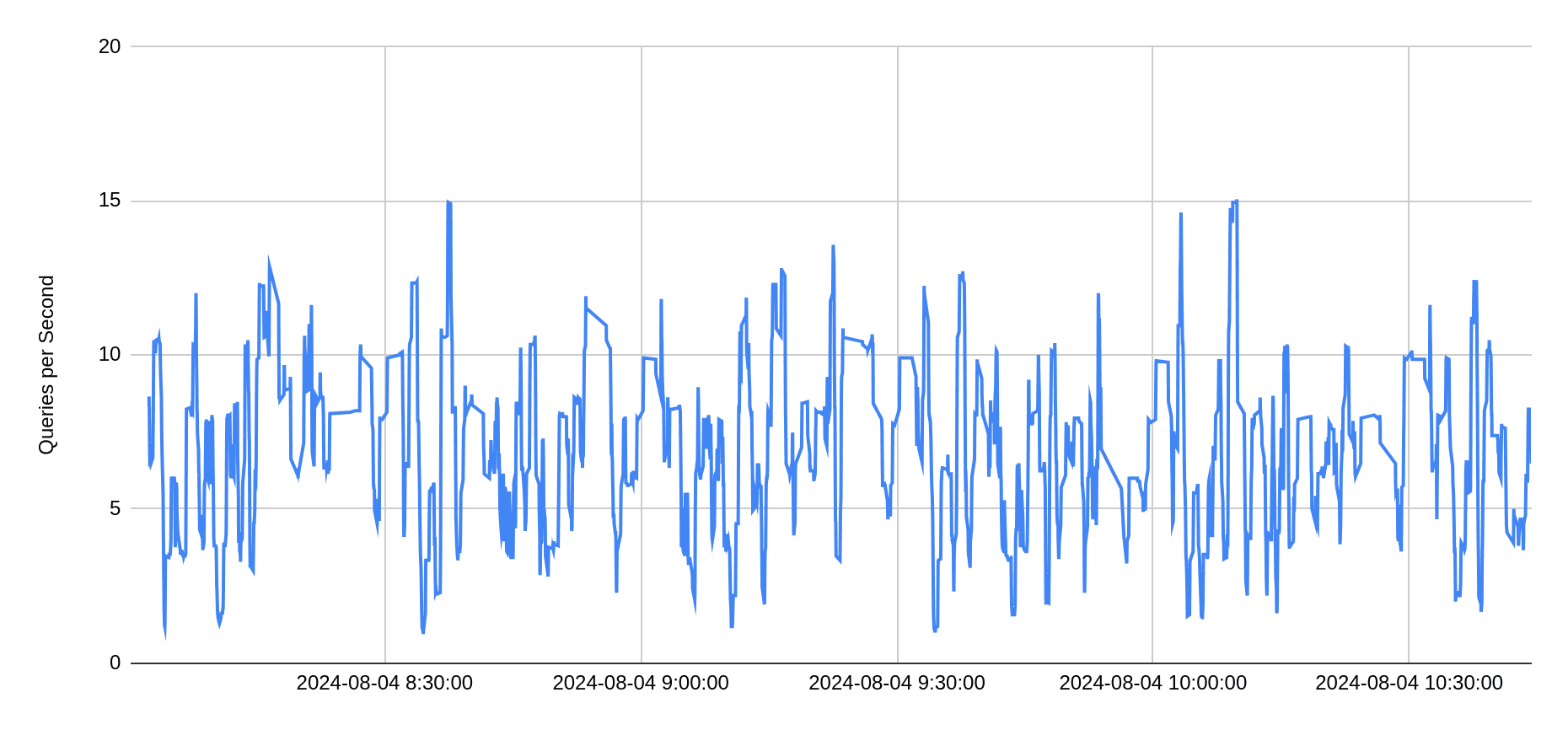
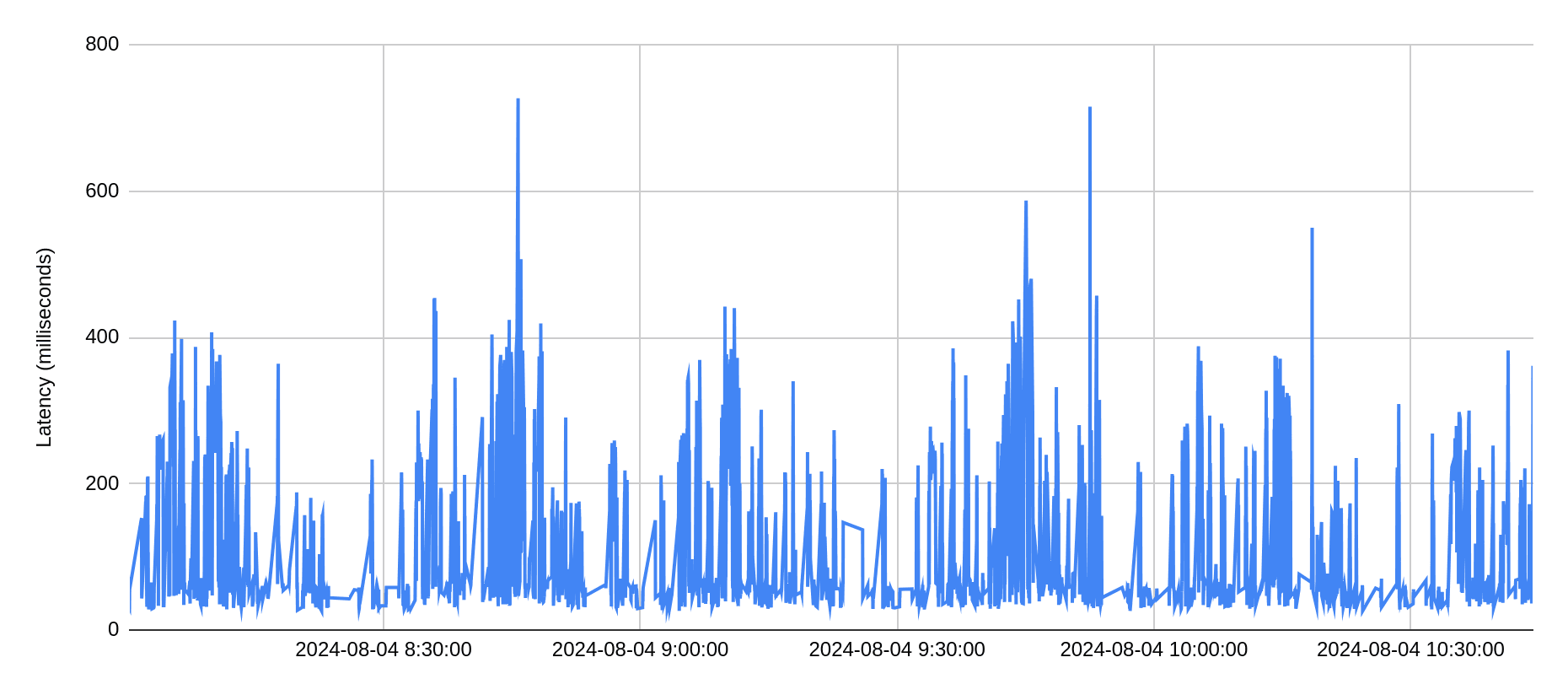
But while performance of DML is important, what is much more important to Firebolt - is performance of reads in the presence of writes. Firebolt is there to support low latency high concurrency data intensive applications, and the latency should remain low even in the presence of updates.
For example, one technique which enables low latency query serving in Firebolt are Aggregating Indexes. Conceptually they are similar to Materialized Views, but with the restriction that they only support a single GROUP BY operator, but with arbitrary aggregate functions. Since Aggregating Indexes contain precomputed results of GROUP BY, query planner can automatically rewrite queries matching (exact or subset) of GROUP BY keys and aggregate functions to redirect them to the Aggregating Index instead of base table.
What should happen with precomputed results during DML - especially for UPDATE and DELETE? It is a tradeoff between write and read latency. Some systems don't update Materialized Views for every DML, and instead recompute them lazily in the background. But we cannot afford doing this in production workloads, because then once DML transaction commits, the subsequent reads will suffer performance drop. So we update aggregating indexes in the same transaction as DML, and we do it incrementally. There is extensive research literature about incremental maintenance of materialized views, particularly the ones containing aggregate functions - [GMS93], [GM99], [DQ96], [MQM97]. These papers are kind of complex to read, but the idea is relatively simple. Incremental update is straightforward to do for "good" functions like SUM. We can compute SUM (optionally per group) for all values in the transaction. For INSERT we simply add it as a new delta, and for DELETE we also add it, but as a negative delta. It is more tricky with more difficult functions, like MAX. It can still be added in INSERT, and we can quickly calculate MAX between the existing values and the delta. But what to do in DELETE - how do we know if we removed the maximum value per group (maybe there are ties), and what the new value would be ? It is possible to mark affected groups as invalid, but it means that they will have to be recalculated for every subsequent SELECT. In the spirit of doing more work at write to optimize reads, instead we selectively recompute values in the Aggregating Index, by natively deleting the old group by entries, and inserting a fresh values from the origin table after filtering the deleted values, but only for groups affected by the DELETE.
## Transaction manager: ACID at no cost
Finally, to be a DBMS, Firebolt needed to support transactions. This is something we couldn't compromise on. Firebolt had to have real ACID transactions, not eventual consistency, not "almost transactional" - but true ACID. There are many ways to build Transaction Manager, but for it to fit the Firebolt mission, we put together the following list of requirements:
- 100% ACID
- Within distributed environment, across multiple compute clusters
- With storage compute separation, where any compute cluster can access any data
- With full support for multiple writers, any node of any compute cluster can modify any data
- Immediate consistency: Once a transaction commits, changes should be immediately visible to all other nodes in all other compute clusters
- Strong Serializable Isolation Level for all metadata operations (DDL, DCL)
- Snapshot Isolation Level for data operations (DML and DQL)
- At scale of analytics, where a single transaction can modify hundreds of terabytes
- But also allow low latency "trickle" DML, i.e. DML updating only a handful of rows few times a second
- Optimize for workloads dominated by reads, with writes being a small fraction of the queries
- Allow long running multi-statement transactions
- Enable transactions to span across multiple databases
And if that was not difficult enough, here is the kicker:
- All the above without performance impact on low latency high concurrency data intensive application workloads
To illustrate the last point - the fastest query that one of our customers is running in production to power their application takes 5 milliseconds. So if the transaction manager's overhead is only 1 millisecond - which would be fantastic achievement given the above requirements, that would still be 20% slowdown, so we strive to reduce transaction manager overhead to zero.
Designing such a system is very challenging, and we are not aware of precedents neither in industry nor in research. One tradeoff that we decided to do very early was to prioritize the "happy" path of the read-only DQL SELECT query. Given that analytical workloads have many more read queries than write queries, we wanted to perform best if there were no changes since the previous query, and we could use all the cached metadata - definition of the schema objects - tables, views, indexes etc; snapshot versions of the data (i.e. list of tablets per table), statistics etc. All we needed was one RPC call to the transaction manager at the start of a read-only transaction to verify that indeed nothing changed, and that cached snapshots are still valid in the new transaction.
Since we were optimizing for read-mostly workloads, but with writes that had to be consistent across all the compute clusters, we decided to persist transaction log (aka Write Ahead Log or WAL) in FoundationDB. FoundationDB is a proven datastore which gave us production readiness, robustness, scalability, fault tolerance and transactional semantics. On top of that, it offers extremely low latency even at the P99 tail. So in a sense, we delegated the most difficult part of transaction management to FoundationDB.
In order to be able to quickly interpret whether changes in WAL impact the current query, we built indexes over WAL which are used by the most common requests to Transaction Manager, including one which checks if anything changed. Not only that, these indexes allow to easily compute a delta of changes, and replay only the relevant portion of the log. Having WAL indexes has the drawback of slowing down transaction commits which need to build these indexes, but it was acceptable to us, since we were optimizing for reads.
Other techniques include having asynchronous notifications about WAL changes post commit, so all compute nodes have a chance to see them and update their snapshot (and possibly prefetch data as well) before a user sends the next query.
We also invested heavily in network topology of our deployment both for Transaction Manager and FoundationDB, to ensure that within a regional deployment, we cross availability zone boundaries at most once.
So coming back to the "happy" path of the query: A compute node that handles a user query needs just one RPC to Transaction Manager to check that nothing has changed, and Transaction Manager uses WAL indexes and reads few FDB keys in parallel to confirm that nothing indeed changed. We target 1 millisecond for that interaction. But even 1 ms could be too much for low latency queries. We plan to optimistically start the query execution in the hope that the cache is up to date. In the unlucky case when it's not - the query execution would need to be canceled and restarted with an updated version of the metadata. This part is still work in progress.
Since Transaction Manager stores all of its state in FoundationDB, it is a stateless service, and scales easily. (Of course, FoundationDB being a stateful service also needs to scale well - but FDB is a very mature technology, and it does scale). We have put our Transaction Manager through stress testing, loading it with tens of thousands of QPS both read and write transactions, and it holds up well.
## Conclusion
In this blog we started with answering the question - what did we build Firebolt for, and why do we think the world needs Cloud Data Warehouse for Data Intensive Applications. Once we articulated our vision, it became very clear what our focus and engineering priorities should be in realizing this vision. We defined our two guiding principles - building a no-compromise analytical DBMS and making it perform the best for interactive, user-facing, low-latency, high-concurrency applications. These principles were guiding us in designing and implementing all components of our system. Like always in engineering, we had to make tradeoffs, and the above principles helped us stay focused on our vision, and make tradeoffs that fit the purpose of our system.
The blog gave a handful of examples of how we navigated these tradeoffs in different components of Firebolt - from the API frontend, to query planner, runtime, distributed execution, storage, and transaction manager. And while we didn't cover many other parts of our system - cloud infrastructure, compute, client SDKs, connectors, security manager, metadata service, control plane etc - they all followed the same principles and decision making process.
We believe that being laser focused on our vision, helped us to build a great product which excels at what it is designed to do. But ultimately - it is up to you - our customers - to judge!
### References
[SHMMKT06] U. Srivastava, P. J. Haas, V. Markl, N. Megiddo, M. Kutsch, and T. M. Tran. ISOMER: Consistent Histogram Construction Using Query Feedback. In ICDE, 2006.
[BCG01] N. Bruno, S. Chaudhuri, and L. Gravano. STHoles: a multidimensional workload-aware histogram. In SIGMOD, 2001.
[BMHM07] A. Behm, V. Markl, P. Haas, and K. Murthy. Integrating Query-Feedback Based Statistics into Informix Dynamic Server. In: Datenbanksysteme in Business, Technologie und Web (BTW), 2007.
[PZM20] Y. Park, S. Zhong, and B. Mozafari. QuickSel: Quick Selectivity Learning with Mixture Models. In SIGMOD, 2020.
[HBEAM18] Zhang, Haoyu and Cho, Brian and Seyfe, Ergin and Ching, Avery and Freedman, Michael J. Riffle: optimized shuffle service for large-scale data analytics. In ACM 2018. https://doi.org/10.1145/3190508.3190534
[SAJHJ19] Qiao, Shi and Nicoara, Adrian and Sun, Jin and Friedman, Marc and Patel, Hiren and Ekanayake, Jaliya. Hyper dimension shuffle: efficient data repartition at petabyte scale in SCOPE, In VLDB 2019, https://dl.acm.org/doi/abs/10.14778/3339490.3339495
[MYC20] Shen, Min and Zhou, Ye and Singh, Chandni. Magnet: push-based shuffle service for large-scale data processing. In VLDB 2020. https://dl.acm.org/doi/abs/10.14778/3415478.3415558
[Inmon02] Inmon W.H. Building the Data Warehouse, 3rd edn. Wiley, New York, 2002
[GMS93] A. Gupta, I. S. Mumick, and V. S. Subrahmanian, "Maintaining views incrementally," In Proceedings of ACM SIGMOD Conference, pp. 157-166, 1993.
[GM99] H. Gupta and IS. Mumick, "Incremental maintenance of aggregate and outerjoin," Technical Report, Stanford University, 1999. https://www3.cs.stonybrook.edu/~hgupta/ps/aggr-is.pdf
[DQ96] Maintenance Expressions for Views with Aggregation Dallan Quass Stanford University, http://ilpubs.stanford.edu:8090/183/1/1996-54.pdf
[MQM97] I. S. Mumick, D. Quass, and B. S. Mumick, "Maintenance of Data Cubes and Summary Tables in a Warehouse," In Proceedings of ACM SIGMOD Conference, 1997. https://dl.acm.org/doi/pdf/10.1145/253260.253277