ON THIS PAGE
## Asynchronous query execution
Asynchronous query execution refers to starting a long running query without holding up the connection in client, whilst receiving a token to reference said query to be able to see it's status in time. This features enables users to not use precious resources on just maintaining a connection when in fact their client is not doing anything.
Applications can't always wait for a submitted query to finish running before moving on. Imagine performing a bulk insert that will take minutes, and your entire logic flow grinds to a halt while waiting for that to complete. Not a good pattern, right? Asynchronous query execution allows you to avoid this problem, submit a query, leave the execution wholly to Firebolt, and move on. This has landed in all of Firebolt's client drivers, ensuring that your client, application, or hardware can get back to tackling tasks while you put Firebolt to work.
How does it work? In the example below, we assume that the Firebolt driver runs in your VPC on an EC2 instance on AWS (it can be on any other cloud or on prem):
Without async execution:
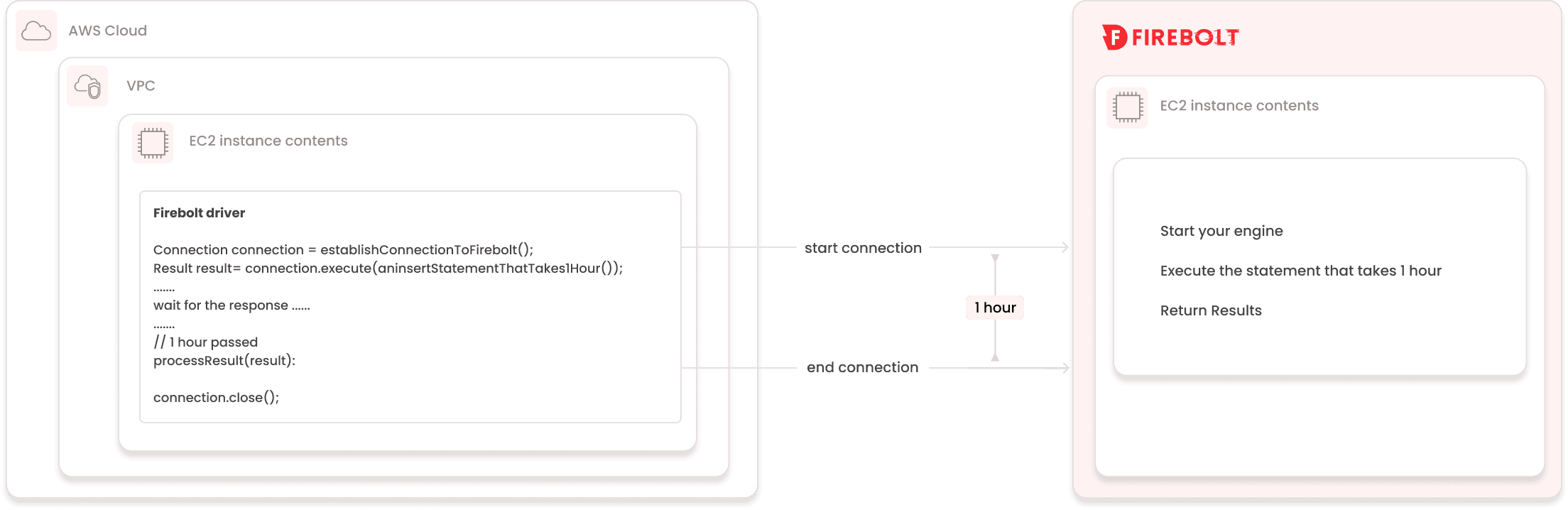
During the time the Firebolt executes the query, in this instance we assume it takes 1 hour to finish, your resource (EC2 instance) will stay up and running, costing you money even though it is not doing anything useful: it is just waiting for the query to finish.
With async execution:
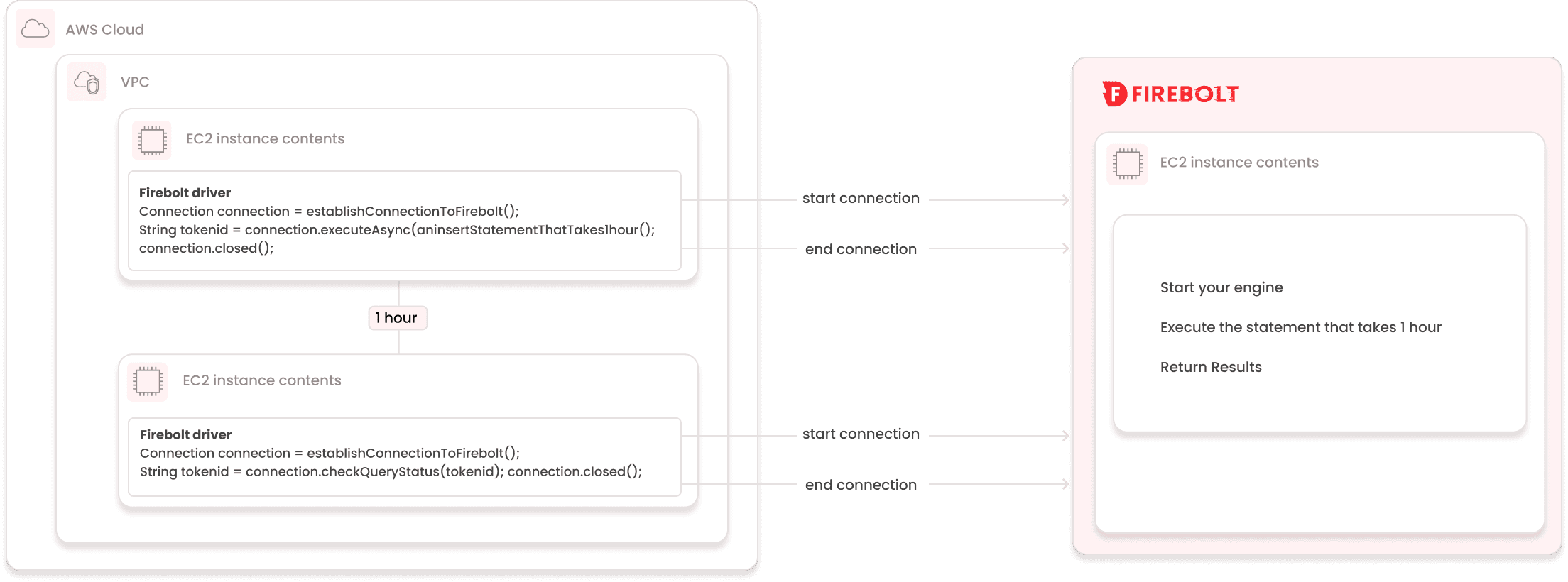
When executing a query asynchronously, the client will get back a tokenId that can be then used to:
- check the status of the initial query
- cancel the initial query (only if the query has not finished by then)
Notice that you can stop your EC2 instance for the duration of the time it takes Firebolt to actually run the query, and then you can bring it up to check the status and continue whatever work you were planning to do.
This approach not only frees up your application's resources, but also introduces real infrastructure cost savings. By decoupling query execution from your client's uptime, you avoid paying for idle compute — which is particularly impactful when running large-scale insertions or transformations that may take tens of minutes or more. You can integrate this flow into an automated lifecycle where your EC2 instance submits the query, shuts down, and then is reactivated via a scheduled job or event trigger to resume downstream processing once Firebolt has completed the work, or once it's time to submit another query.
The diagrams above illustrate both approaches: the first shows how your EC2 instance stays active (and incurring cost) throughout a synchronous query; the second highlights how asynchronous execution lets you pause client-side activity while Firebolt completes the task independently.
Implementing it with our clients isn't very difficult, either:
// Statically typed drivers require the user to cast/unwrap classes to the Firebolt implementationFireboltConnection connection = DriverManager.getConnection(url, clientId, clientSecret).unwrap(FireboltConnection.class);try (FireboltStatement statement = connection.createStatement().unwrap(FireboltStatement.class)) { statement.executeAsync("INSERT INTO table SELECT checksum(*) FROM GENERATE_SERIES(1, 2500000000)"); //long running query String token = statement.getAsyncToken(); //token from which you can identify the query by //checking query running status boolean isRunning = connection.isAsyncQueryRunning(token); boolean isSuccessful = connection.isAsyncQuerySuccessful(token) //you can also cancel the query execution if it is still running connection.cancelAsyncQuery(token); //this should return true if the query was cancelled}// But dynamically typed drivers do not have this issueconst statement = await connection.executeAsync( "INSERT INTO table SELECT checksum(*) FROM GENERATE_SERIES(1, 2500000000)", executeQueryOptions,);const token = statement.asyncQueryToken; // used to check query status and cancel it and can only be fetched for async query//checking query running statusconst isRunning = await connection.isAsyncQueryRunning(token);const isSuccessful = await connection.isAsyncQuerySuccessful(token);//you can also cancel the query execution if it is still runningawait connection.cancelAsyncQuery(token);## Streaming query results
If you're querying massive datasets, sometimes you're also working with large result sets. Not every query has a LIMIT 10 at the end — and if you're reading a million rows or more, this can pose a very real challenge when it comes time to actually work with the results. A naive implementation might simply return the entire dataset to the client all at once. That could work for smaller queries, but with large outputs, it's a fast track to running out of memory, triggering crashes, or severely degrading performance.
But with streaming, Firebolt handles things differently. Instead of delivering the full result set in a single payload, it streams rows in manageable chunks. Your application doesn't need to hold the entire dataset in memory — it can start processing as soon as the first rows arrive, consuming them incrementally in a forward-only fashion. This makes it not only safer (no memory overflows), but also faster in practice, since you can begin working with the data before the entire query completes.
This approach is ideal for ETL pipelines, large data exports, or any kind of batch process where the size of the result isn't known ahead of time — and where robustness is just as important as speed. Firebolt drivers and SDKs provide this functionality in a simple manner, keeping the driver-intended way of parsing results, but not actually storing the entire result at once.
Streaming becomes especially important in production environments where reliability and scalability matter. For example, if you're building an analytics API that returns results to end users or pushing query results into a downstream system like S3, Kafka, or a data lake — you're likely dealing with large, unpredictable volumes of data. Without streaming, you'd be forced to manually implement workarounds like pagination or break your queries into smaller chunks, adding complexity and latency. With streaming, Firebolt handles that complexity for you behind the scenes, so your application can simply iterate over rows as they arrive, no special logic required.
What's more, streaming isn't just about protecting against crashes — it's also about responsiveness. Because data arrives as it's ready, your application can begin transforming, displaying, or transferring the output without waiting for the full query to complete. That improves time-to-first-byte and makes your system feel faster and more responsive to users — especially valuable in dashboarding tools or real-time reporting interfaces. In short, streaming transforms how your app consumes data: from waiting and hoping, to processing and scaling.
On the topic of error handling, you do lose the ability to know before receiving the results if there were any errors encountered during processing (i.e.: select 1/(i-100000) as a from generate_series(1,100000) as i), but each driver provides mechanisms for not generating exception vulnerable code even though an error may be encountered in the middle of the result set.
JDBC supports result streaming by default, so the statically typed driver presented here will be .NET:
FireboltCommand command = (FireboltCommand)conn.CreateCommand();command.CommandText = "SELECT * FROM large_table";// Execute the query without storing the whole result in memoryusing var reader = command.ExecuteStreamedQuery();// or use the asynchronous versionusing var reader = await command.ExecuteStreamedQueryAsync();// Iterate over the streamed results in the same way as with a regular DbDataReaderwhile (await reader.ReadAsync()){ //process results with reader.GetValue(x) for example}// JavaScript's implementation leverages its streaming templateconst statement = await connection.executeStream(`select 1 from generate_series(1, 2500000)`);const { data } = await statement.streamResult();data .on("meta", (meta) => { //store/process meta }) .on("data", (row) => { //process data }) .on("error", (err) => { //capture error });## Server-side prepared statements
If your application accepts user input — whether it's a search box, a filter in a dashboard, or a dynamically generated report — chances are you're constructing SQL queries on the fly. And when you're doing that, you're also opening the door to potential vulnerabilities like SQL injection. A common approach to mitigate this is to use parameterized queries, where user values are passed separately from the SQL structure. But even then, where and how those parameters are handled makes a difference — and that's where server-side prepared statements come in.
With server-side preparation, the Firebolt engine — not your application — is responsible for securely binding parameters. You send the SQL statement with placeholders, and the actual parameter values are passed separately. Firebolt compiles the query and injects the values safely on the server, eliminating the risk of those values being interpreted as part of the SQL logic. This setup adds a layer of security by removing the burden from your application code and protecting against common injection attack vectors.
It's also worth noting that server-side prepared statements don't just improve security — they can also improve performance. Since the query structure is compiled and cached by Firebolt, repeated executions of the same statement with different parameters can reuse the same execution plan. This is especially valuable for multi-tenant apps, dashboards, or reporting tools that generate the same query with slightly different inputs. With fewer parsing and planning steps, your queries run faster and more predictably.
Firebolt also uses this feature to help standardize how parameters are defined across all supported drivers. While most languages and frameworks have their own syntax for prepared statements — like ?, :name, or %s — Firebolt's server-side prepared statements use a numbered placeholder format like $1, $2, and so on. This consistent format helps reduce confusion across languages and environments, making it easier to maintain query templates in a shared codebase. It also improves readability and makes the logic behind parameter ordering explicit.
That said, Firebolt still supports the native client-side style of prepared statements if you prefer — and in fact, it's the default for many drivers. You can continue using the syntax that matches your language of choice, and the driver will substitute parameters before sending the final query to Firebolt. But if you want to take advantage of server-side preparation — for the added security, performance, and standardization — you'll need to update your queries to use the $1, $2, etc. format and enable the appropriate mode in your client.
In short, server-side prepared statements help you build safer, more efficient applications — while encouraging best practices and consistency across teams, drivers, and use cases.
Two different ways of implementing them:
// Besides GO, all languages need one more element in the connection string to make the connection server-side prepared statement ready. In this case we have prepared_statement_param_style=fb_numeric (the native option is the default, but you could specify it in the connection string if you want)Connection connection = DriverManager.getConnection("jdbc:firebolt:my_db?account=...&prepared_statement_param_style=fb_numeric....", clientId, clientSecret);try (PreparedStatement statement = connection..prepareStatement("select $1, $2")) { statement.setInt(1, 2); statement.setString(2, "foo"); ResultSet rs = statement.getResultSet(); //then process result}//Node.js allows you to make use of both parameters and namedParameters, but not both at the same timeconst connection = await firebolt.connect({ ...connectionInfo, preparedStatementParamStyle: "fb_numeric", //important});const statement = await connection.execute("select $1, $2", { parameters: ["foo", 1], //using the parameters executeQueryOptions field});const statement = await connection.execute("select $1, $2", { namedParameters: { $1: "foo", $2: 123 }, //using the namedParameters executeQueryOptions field});## Conclusion
Every driver has these features implemented and they are all ready to improve your experience with Firebolt, be it by a resource freeing aspect, a memory holdup one, or just better security. For better explanations please refer to the driver's documentation and if needed, don't hesitate to contact us!