In general, aggregations are grouping functions. Instead of returning single-row or single-document data, the response is grouped by a certain criteria. The most common case is the faceted search on an ecommerce shop like amazon.com. After you have searched for something like a new TV, part of your results page contains information on how many products were found for each brand or for each display size — allowing you to reduce the result further by using brand or dimensions as a filter for your product selection. There are many technology solutions to handle aggregations, and each technology handles aggregations differently. Different implementations are covered in the following sections.
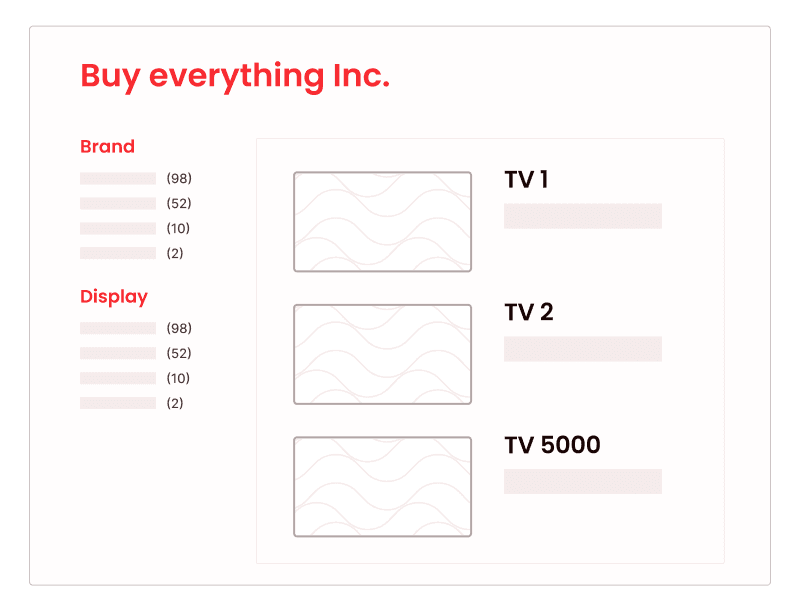
The above image features three different information retrieval parts. First, the list of TVs on the right side. Second, the brand selection and count, and third, the display size selection and count. The last two are aggregations.
## Examples of Aggregations
Use of relational databases to store and retrieve data using Structured Query Language (SQL) is a very prevalent and proven approach. In the SQL world, an aggregate function collects a set of values and returns a single number. The most common ones are probably COUNT, MAX, MIN, SUM and AVG in combination with a grouping criteria in a GROUP BY statement or using WINDOW functions.
Translating SQL into aggregations of other data stores or vice versa shows the complexity due to subtle differences. Starting with some SQL for the above ecommerce example, each query fetches a part for the web page to display. First, the products on the right, then the two aggregations based on brand and display size on the left:
Elasticsearch provides another approach to searching through piles of data. Taking a look at Elasticsearch (or OpenSearch aggregations for that matter), the above e-commerce use case can be implemented with a search request using the JSON query DSL (domain specific language). This request fetches data that contains aggregations for each criteria on the left as well as results.
NoSQL databases, such as MongoDB, are another approach to information storage and retrieval. In MongoDB, aggregations have a different syntax than the nested JSON approach from Elasticsearch, using function names preceded by a $ sign. There is a dedicated $facet aggregation for this very common use-case to simplify the way the query is written. This shows one query for the aggregated data and another for retrieving the search results.
## Challenges with aggregations
Aggregations may need to read through a lot of data and can take significant time to compute. Pre-aggregating data, Materialized Views in SQL for example, is a common trick to speed up retrieval of aggregate data. The trade-off is that the aggregates may not reflect the current state of the system. In the use case above, if the inventory was pre-aggregated 12-hours ago, the aggregate search might reflect stale data and show that a product is available when it is really out-of-stock. When calculating aggregations, the trade-offs between fresh data, performance and technology choices should be considered. Not all technologies perform the same way when dealing with pre-aggregations.
Additionally, when dealing with large amounts of data, most technologies require significant compute and memory to calculate aggregations. Some implementations overflow to disk once a certain amount of data is exceeded in memory, other data stores abort the request to prevent running out of memory and remain responsive for other requests or allow for background execution instead of waiting for the request to be completed and blocking the connection. Check your data store implementation to be sure it can handle the amount of data.
Another approach to speeding up aggregations is the use of probabilistic data structures, also called data sketches. Usage of those results in counts, distinct counts or quantiles not being a hundred percent exact. The reason for this is the ability to run such calculations on data on different nodes and then merge the results together without having all the data centralized on a single system, which would be necessary using the naive approach. This also makes it harder to compare the output of two different data stores to ensure that you have written the same query for two different data stores.
Transactional consistency is another aspect that can have an impact on the aggregate data returned. Data modifications may have happened between two requests. In this example this might lead to different counts of your displayed results, which in this case is not a big issue.