

Listen to this article
How to enable sub-second analysis across billions of rows of customer behavior data.
This article is intended for Data Engineers who are already familiar with dbt and have access to a Firebolt account. If you are new to dbt then we recommend starting with the Jaffle Shop example (https://github.com/dbt-labs/jaffle_shop). If you don’t have a Firebolt account then please read through this post and then contact Firebolt Sales to start a trial.
Part I - Setting up the load
Snowplow Analytics is a leading provider of customer behavior data, offering a wide variety of trackers to collect data from all of your interactions with your customers. That data is then collected, organized, validated and enriched to provide valuable insight. One of the primary methods for understanding customer behavior is time series analysis, measuring the changes in behavior over time. Due to the volume of the data, analyzing even a few months of data requires a data platform built for scale.
Firebolt offers the ability to analyze billions of rows of data without having to aggregate or waste time waiting for long-running queries. Snowplow data is well-organized and has a column structure that fits well with Firebolt’s indexing strategy. Together these two technologies offer a flexible way to analyze web and mobile event data to better understand your customers behavior and its impact on your business.
A “blueprint” for loading into Firebolt
In this post I will present a blueprint of how to set up a dbt project to load Snowplow data into a Firebolt database. Because there is not currently a way to load directly from Snowplow into Firebolt, this blueprint assumes that the Snowplow data is being pushed to an S3 bucket on a regular basis. I will share a dbt project that loads the data into a Firebolt table including a primary index and an aggregating index. This blueprint can be adapted to your environment based on your specific needs. In the next part of this series I will share how to automate the load using Prefect Cloud.
We will use JSON as the format for the Snowplow data because it simplifies the definition of the Firebolt external table and Firebolt has built in JSON processing functionality. On the other hand, Snowplow recommends a defined column structure to provide optimized query performance. Additionally, Firebolt’s native file structure is columnar and its indexes work best on predefined columns. As a result, the key logic in this example is the query to parse the JSON into a columnar fact table.
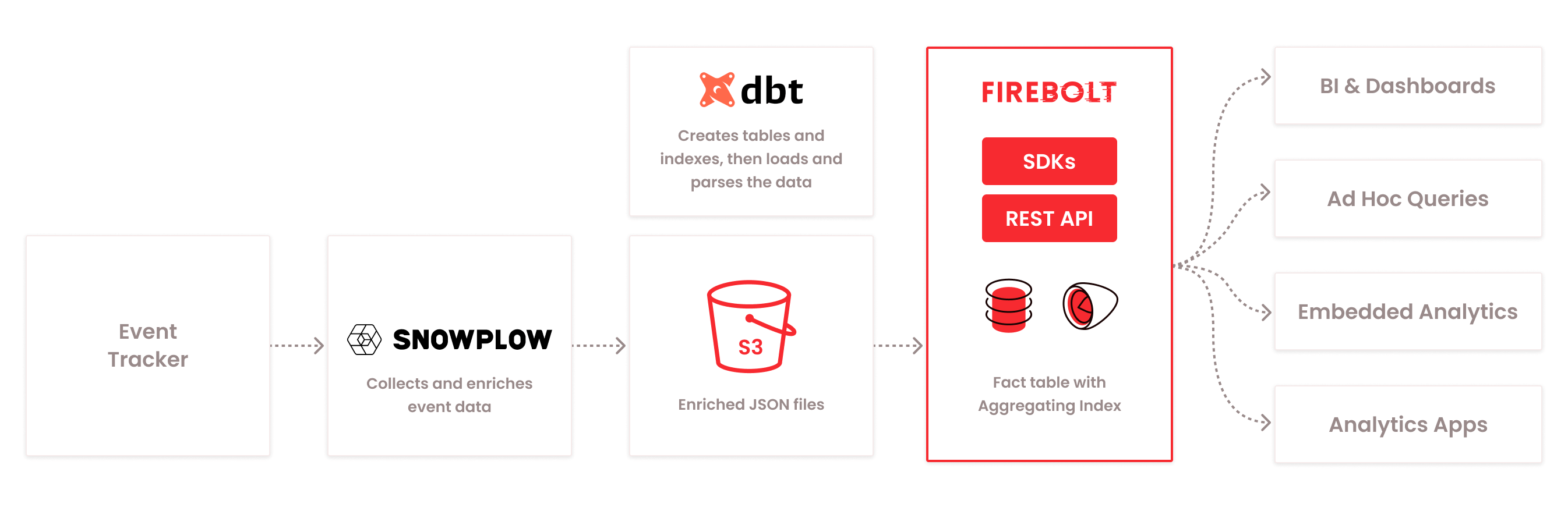
The most recent release of the dbt-firebolt adapter adds support for incremental loading. This is key because the data is large enough that it would be inefficient to reload all of the data with each load. Leveraging dbt allows us to separate the table structure and index design (contained in the model SQL files) from the scheduling and execution code (python scripts).
Setting up dbt
Let’s start by installing the dbt-firebolt adapter on our server, which in this case is my Macbook but could also be a basic EC2 instance. This way we can validate the load before we set up the schedule. If you use pip to manage your Python packages, the below syntax will install the latest version.
% pip install --upgrade dbt-firebolt
Navigate to ~/.dbt and add the following to the profiles.yml file. If the folder or file does not exist then create it.
With the adapter installed and a profile set up, you are ready to clone the repository and get started. I will walk you through the key files in the repository.
The most important file is dbt_project.yml.
Note that the profile name must match a profile in your profiles.yml file above. Some of the paths in this file do not exist in the repository but will be created by dbt.
The next file is packages.yml.
Once these files are in place, you will need to run the dbt deps command and your output should match the example below.
Now that the project is configured and the dependencies have been loaded, it is time to discuss the model file sources.yml defines the external table for this project.
In this case there is only a single table with a single column of type TEXT. However you can define multiple external tables within this file. With this configuration, the external table will return one row for every top level JSON object in the files in the specified S3 location. The Name attribute will be used as the name of the external table and a best practice for Firebolt is to use ‘_ext’ as a suffix for external table names. The URL attribute should point to the S3 bucket and folder where your files are located. The Object_Pattern attribute is used to exclude any files in that path that don’t contain table data. This example does not include credentials for the S3 location, but you can either use an AWS Key ID and Secret Key or an IAM Role. For details visit our documentation.
For every fact or dimension table to be created, there needs to be a .sql file whose filename is the name of the table. This file has a header that defines the table settings and then a SELECT statement that will be used in a CTAS statement to generate the table. Snowplow_events_fact.sql defines the logic that will be used to create and populate the Snowplow_events_fact fact table.
In this case we only have a single table, but this table has over 100 columns so the query is very complicated. All of the columns represent data that is parsed from the JSON object associated with each row. COALESCE is used for most columns to prevent NULL values from being written to the table as they reduce the effectiveness of the indexes. Additionally we have chosen ‘incremental’ as the materialization because we want to only load the new records after the initial run.
There are three indexes defined in this example based on query patterns that seemed natural for this data. The primary index consists of 5 columns that would likely be used to filter the data when querying this table. We included a date field in the SQL as well as a timestamp for the collector timestamp to reduce the cardinality of that column.
The first aggregating index groups by app_id and platform, while the second groups by session_id. This is to support querying by either one of those patterns. Both aggregating indexes have a number of count distincts included because they represent significant metrics for event data. Any of these indexes could easily be modified if additional query patterns were identified.
Loading the data
With all these pieces in place, we are ready to run the project. Remember to start the engine before running the following steps. I am including the commands and their output for reference. First we should run dbt debug to validate our project.
Next we run stage_external_sources to create the external table.
In the Firebolt UI we can validate the table that was created by running a simple ‘select’
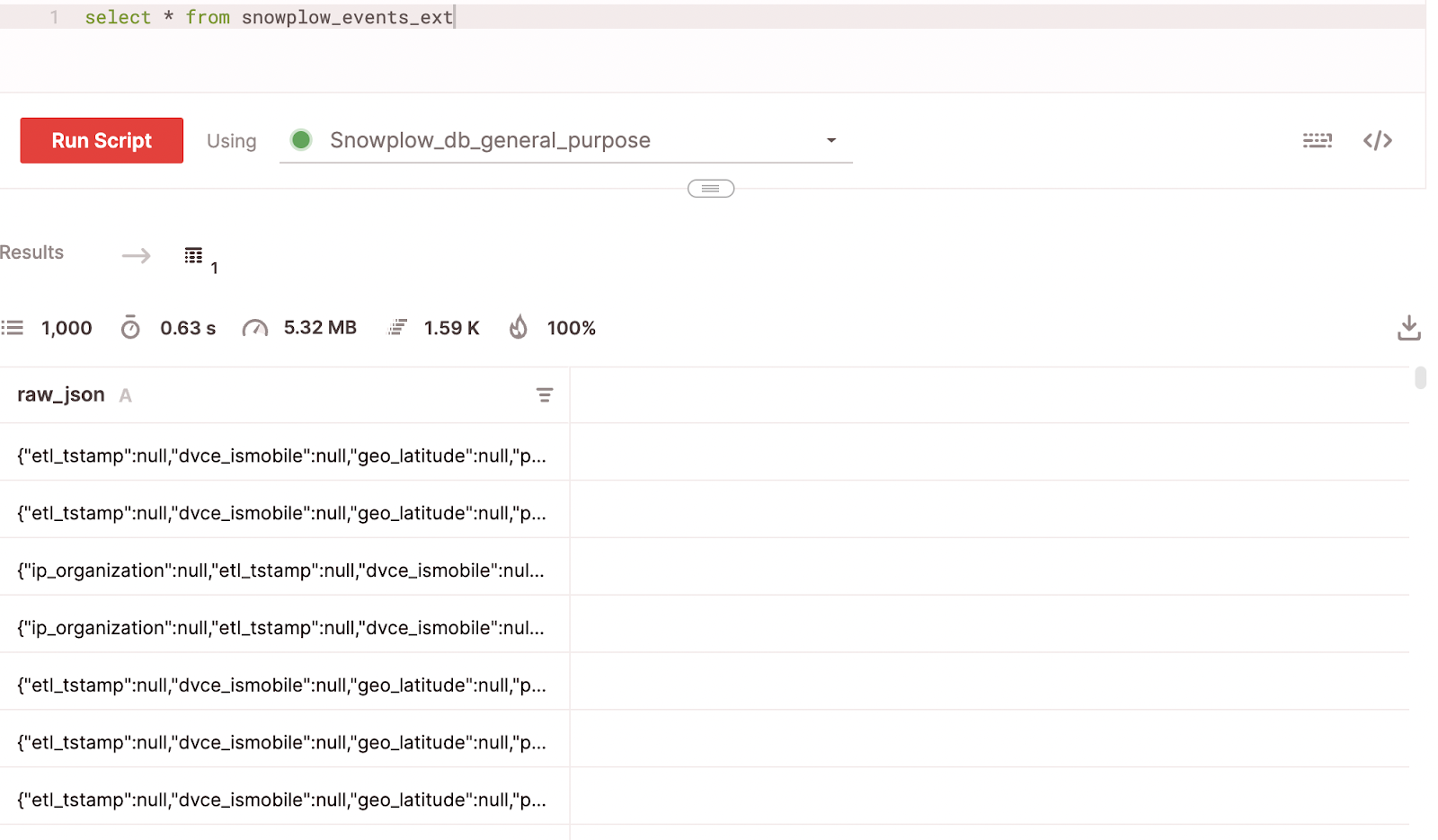
Note that JSON data is read as multiple rows based on the top-level structure of the file. Now that the external table is ready, we can run the project.
Querying the data
Now that the data is loaded into a fact table, we are ready to query it to learn about the behavior of our customers. First we want to determine the average number of page views and time engaged in seconds per session. To do this we first need to organize the data into sessions using a CTE, then we can calculate those metrics with a simple query. Because we included session_id in one of our aggregating indexes, this query runs sub-second over millions of rows.
Conclusion
We have now created a process for loading Snowplow data into Firebolt, including a Primary index and two Aggregating Indexes. All commands and files needed to implement this process are included for reference. In the next part of this series I will demonstrate how to automate this load using Prefect Cloud. Please reach out to the Firebolt sales team to learn more and try it out for yourself.
