ON THIS PAGE
- Why storage layout matters for analytical workloads
- How columnar storage works
- Column-based layout: storage and retrieval
- Compression techniques in columnar storage
- Execution optimizations: why it's so fast
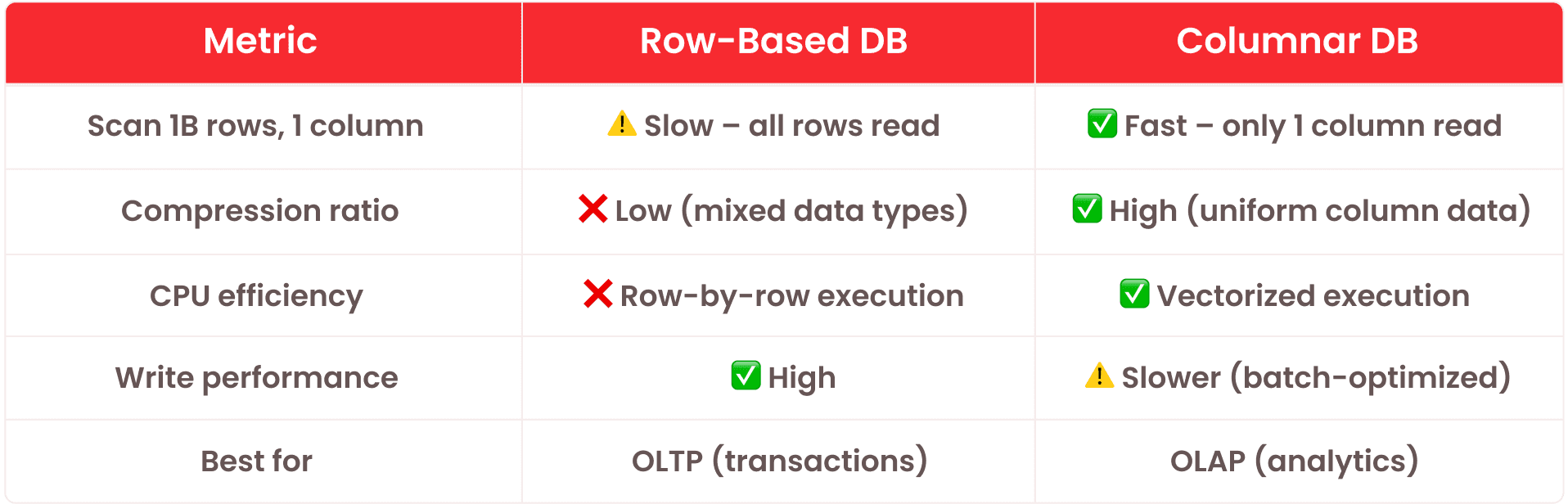
- Columnar vs row-based storage: what's the difference?
- Row-based storage: optimized for OLTP
- Columnar storage: optimized for OLAP
- Benchmark highlights: query speed & storage footprint
- Benefits of columnar storage
- Columnar file formats: what you should know
- Columnar storage in Firebolt: what makes it different?
- Proprietary file format and performance layer
- Indexes that accelerate performance
- Firebolt architecture overview
- Best practices for implementing columnar storage
- Schema design tips
- Partitioning and indexing
- Handling large datasets and cold data
- Common misconceptions about columnar storage
- "It's only for big data"
- "It doesn't support real-time"
- "It's not developer-friendly"
- Conclusion
- FAQs
- What is columnar storage in a database?
- How is columnar storage different from row storage?
- Why is columnar storage faster?
- What companies use columnar storage?
- How does Firebolt utilize columnar storage?
Columnar storage is a data organization technique where data is stored and retrieved by column rather than by row. While traditional row-based databases write complete records contiguously on disk, columnar databases group and store each column's values together — which has huge implications for performance, compression, and parallelism.
If you're new to databases or trying to squeeze better performance out of your analytics, you've probably heard about columnar storage. But what is it, really?
In other words, columnar storage means storing your data by column instead of by row. That might sound like a minor difference, but it has a huge impact on performance — especially when you're running analytical queries on large datasets.
## Why storage layout matters for analytical workloads
To understand the impact of storage layout, think about how analytical queries work. These queries often:
- Scan billions of rows
- Touch only a small subset of columns
- Perform aggregations (e.g.,
SUM,AVG,COUNT)
In a row-based system, every row must be read in full, even if the query only needs a single column. That results in unnecessary I/O and slower performance.
In contrast, columnar storage reads only the relevant columns — skipping everything else. This dramatically reduces disk I/O, speeds up scans, and enables vectorized execution.
Columnar formats also benefit from:
- High compression ratios (since column values are similar in type and distribution)
- SIMD optimizations (processing many values at once in memory)
- Late materialization (delaying row reassembly until necessary)
These architectural features make columnar storage ideal for OLAP-style workloads — think dashboards, metrics reporting, data exploration, and ML feature prep — not transactional workloads.
Row storage:

Column storage:

## How columnar storage works
At a high level, columnar storage organizes data so that each column is stored independently, often in its own physical block or file segment. This separation unlocks a series of optimizations that dramatically improve performance for read-heavy workloads — especially analytical queries. Let's break it down.
### Column-based layout: storage and retrieval
In a columnar database, instead of storing complete rows one after another, each column's values are stored contiguously. This means:
- You can read only the columns you need, skipping the rest entirely (this is called column pruning).
- It's easier to compress data, since values in a column tend to be similar (more on that next).
- Execution engines can apply SIMD and vectorized processing, scanning through columnar data blocks with higher CPU efficiency.
For example, consider this table:

Instead of storing it row-by-row, a columnar engine stores it like this:

If you run a query like SELECT AVG(age), only the Age column is scanned — saving I/O and compute.
### Compression techniques in columnar storage
Because columns contain similar data types and value ranges, columnar formats unlock high compression ratios. Some common techniques include:
- Run-Length Encoding (RLE): Stores repeated values as a single value + count.
- Example:
[US, US, US, UK]becomes[(US, 3), (UK, 1)]
- Example:
- Dictionary Encoding: Replaces values with a reference to a dictionary.
- Example:
[US, UK, US]→ Dictionary:{0=US, 1=UK}→ Encoded:[0,1,0]
- Example:
- Bit-Packing & Delta Encoding: Efficient for numeric columns with small value ranges or sorted data.
The result? Smaller data blocks, faster reads, and lower memory usage — all critical for analytical queries.
### Execution optimizations: why it's so fast
Columnar engines typically support:
- Column Pruning: Only load columns referenced in a query.
- Predicate Pushdown: Apply WHERE clauses early to avoid loading irrelevant data.
- Vectorized Execution: Process data in batches (vectors) rather than row-by-row, boosting CPU throughput.
- Late Materialization: Delay reassembling rows until absolutely necessary, keeping the engine operating on compressed, columnar formats as long as possible.
All of this contributes to sub-second query performance — especially for aggregation-heavy workloads.
## Columnar vs row-based storage: what's the difference?
When evaluating database architectures, one of the most important choices is how data is physically laid out: row-based or columnar. Each has its strengths — and they serve very different purposes.
### Row-based storage: optimized for OLTP
In row-based databases (think Postgres, MySQL, or SQL Server), each row is stored as a complete record. This is ideal for:
- Transactional workloads (OLTP) where the application frequently inserts, updates, or reads full records.
- Use cases like order processing, user authentication, or point-of-sale systems.
Example:
SELECT * FROM users WHERE user_id = 123;A row store retrieves the entire record in one read — efficient and predictable. Also, transactional databases often normalize data into many tables and use joins, which row stores handle well on a per-row basis. The strength of row stores in OLTP comes from their ability to retrieve or modify entire records quickly, and to do so concurrently for many users. They ensure fast commit times and low-latency point queries. For example, a Postgres or MySQL database can easily handle thousands of short transactions per second for an e-commerce app, each reading or writing just a few rows.
### Columnar storage: optimized for OLAP
In columnar databases (like Firebolt, Redshift, or BigQuery), data is stored column-by-column, which:
- Reduces I/O by scanning only the columns needed
- Improves compression and query efficiency
- Enables vectorized execution, increasing throughput
This makes columnar storage the go-to choice for OLAP-style workloads — dashboards, aggregations, BI queries, and ML pipelines. These queries are read-heavy, often performing calculations (SUM, AVG, MAX, etc.) over large columns and involving filtering on certain dimensions (e.g. sales in Q4 for retail category). Columnar storage is optimized for this pattern: it can read through billions of values in a single column extremely fast, especially with compression and vectorized processing.
Example:
SELECT AVG(sales) FROM transactions WHERE region = 'West';Only two columns (sales, region) are read and processed — no full-row overhead.
## Benchmark highlights: query speed & storage footprint
Let's compare row vs columnar performance in typical analytical workloads:
Explore Firebolt's benchmark results
## Benefits of columnar storage
When queries only touch a few columns out of potentially hundreds, columnar storage avoids reading unnecessary data. This leads to:
- Lower disk I/O
- Smaller data scans
- Faster execution times
Whether you're filtering millions of records or aggregating over time, columnar engines can deliver results in sub-seconds, even at scale.
Storing similar data types together allows columnar systems to use highly effective compression techniques like Run-Length Encoding (RLE) and dictionary encoding.
This results in:
- Smaller data footprints
- Lower storage costs
- Less memory consumption during query execution
Compressed data also means faster reads since there's less data to move from disk to memory.
Columnar storage lends itself naturally to vectorized execution, where operations are performed on batches of values instead of row-by-row.
It enables:
- SIMD (Single Instruction, Multiple Data) CPU acceleration
- Parallel scans across columns
- Better cache utilization
The result? Higher throughput and better performance on modern hardware — especially when running complex aggregations or filtering large datasets.
Columnar databases shine in OLAP scenarios, including:
- Real-time dashboards (fast metrics retrieval)
- Time-series analysis (e.g., tracking trends over time)
- Aggregations and filtering (e.g., SUM, AVG, GROUP BY)
If your workload involves slicing and dicing large volumes of data — think BI tools, product analytics, ML feature engineering — columnar is almost always the right choice.
## Columnar file formats: what you should know
Columnar storage isn't just about how databases organize data internally — it also applies to how data is serialized and exchanged across distributed systems. That's where columnar file formats come in.
If you're working with tools like Spark, Presto, or data lake architectures, chances are you've come across formats like Parquet, ORC, or Arrow. Each was designed to optimize read performance, compression, and interoperability — but they have trade-offs worth knowing.
Let's break down the three most commonly used formats in modern data pipelines:
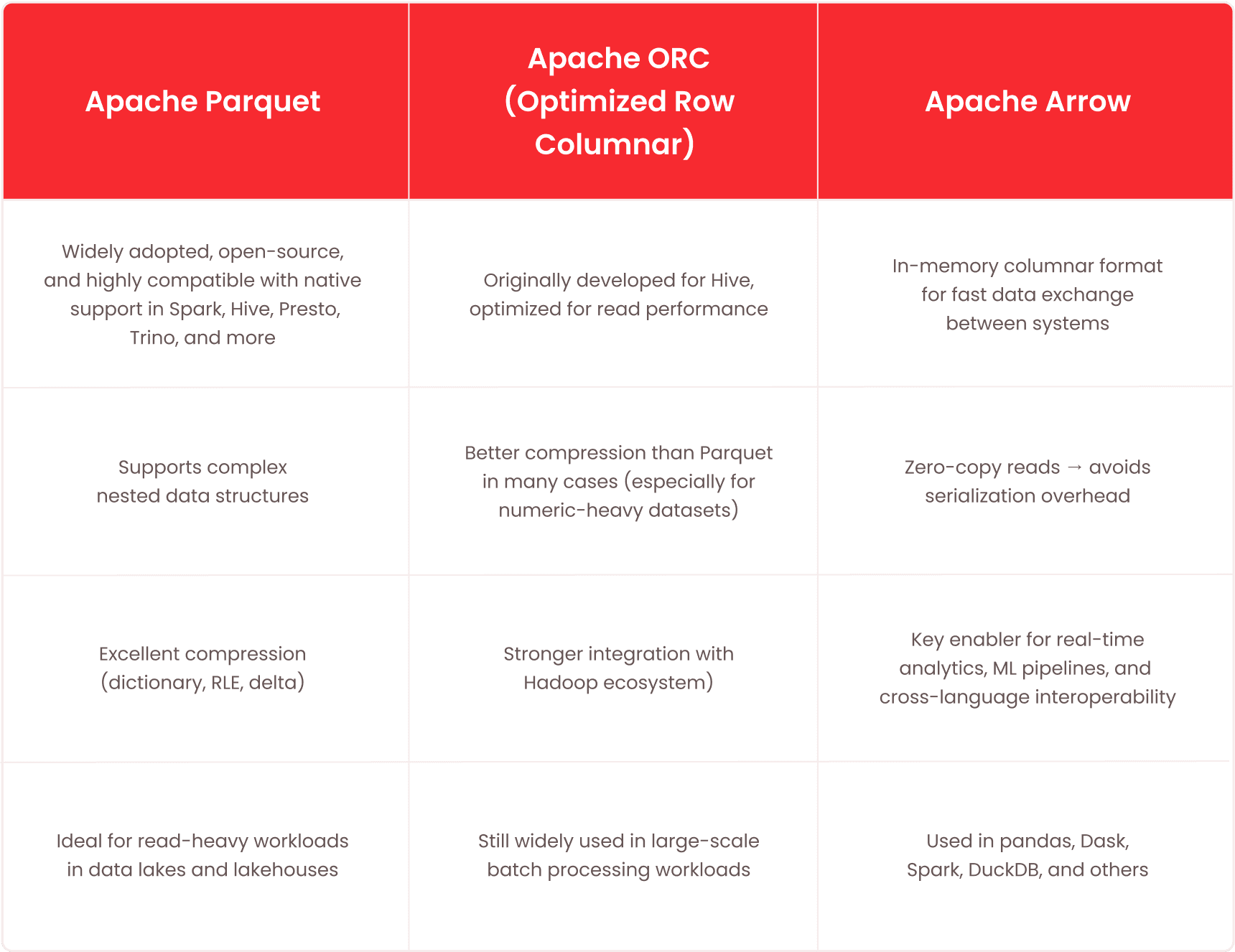
Each format is optimized for specific use cases:
| Format | Best For | Compression | Read Speed | In-Memory? | Tooling Support |
|---|---|---|---|---|---|
| Parquet | General-purpose, lakehouses | ✅ High | ✅ Fast | ❌ No | ✅ Broad |
| ORC | Hive, numeric analytics | ✅ Very High | ✅ Fast | ❌ No | ⚠️ Ecosystem bias |
| Arrow | Real-time, in-memory pipelines | ⚠️ Lower | ⚡ Fastest | ✅ Yes | ✅ Growing |
Choose the format based on:
- Whether your workload is batch or real-time
- How important compression is for your storage layer
- Whether the system requires in-memory data sharing
## Columnar storage in Firebolt: what makes it different?
Firebolt takes columnar storage to the next level by combining a proprietary file format, aggressive indexing, and a high-performance execution engine to deliver ultra-fast analytics at scale.
### Proprietary file format and performance layer
Firebolt stores data in its own optimized columnar format (F3), designed for cloud-native performance. Data is automatically sorted, compressed, and indexed as it's ingested. Firebolt also adds a performance caching layer: recently accessed data is pulled from cloud storage into fast local SSD and RAM, minimizing latency and maximizing throughput.
### Indexes that accelerate performance
Unlike traditional columnar databases that rely mostly on brute-force scans, Firebolt uses indexes as a first-class performance booster:
- Sparse indexes (primary indexes) allow Firebolt to skip large chunks of irrelevant data by organizing tables in sorted order.
- Aggregating indexes precompute common aggregation queries like SUM, COUNT, and AVG, eliminating the need to scan entire tables during analytics.
This indexing approach drastically reduces the amount of data scanned and processed, leading to consistently sub-second queries even at massive scale.
### Firebolt architecture overview
Firebolt separates storage, compute, and metadata into distinct layers for maximum scalability. Data lives in low-cost object storage, while compute engines are spun up or down independently based on workload needs. During queries, Firebolt prunes data aggressively using indexes, retrieves only relevant compressed column chunks, and processes data using vectorized, massively parallel execution across compute nodes — delivering cloud-native analytics performance far beyond traditional columnar systems.
## Best practices for implementing columnar storage
Columnar storage unlocks major speed and efficiency gains for analytics, but realizing its full potential requires thoughtful implementation. From schema design to indexing strategy, making smart choices upfront ensures you maximize performance and minimize costs. Here are the key best practices every data engineer should follow:
### Schema design tips
Columnar databases work best when schema design aligns with how data is queried and scanned.
- Favor wide tables: Store related attributes together to reduce costly joins. Columnar storage handles wide tables efficiently because queries only scan needed columns.
- Use efficient data types: Smaller, more appropriate types (e.g., INT over BIGINT) save storage and enhance compression, speeding up queries.
- Flatten where practical: A moderate level of denormalization can drastically improve analytic query performance by reducing join complexity and avoiding excessive data movement.
### Partitioning and indexing
Proper partitioning and indexing are critical for query pruning and fast scan performance in columnar databases.
- Partition by common filter columns: Choose partition keys that match typical query filters (like event_date, region, or customer_id) to skip irrelevant data quickly.
- Define primary/sparse indexes wisely: Set sort keys on columns most often used in filters or ranges. This enables the engine to prune data aggressively instead of scanning full columns.
- Leverage aggregating indexes: Precompute aggregates for frequent queries (e.g., daily sales totals) to deliver sub-second performance even on massive datasets.
### Handling large datasets and cold data
Scaling columnar storage effectively means balancing performance with storage optimization over time.
- Store cold data efficiently: Compress and archive historical or infrequently accessed data to reduce storage costs without sacrificing access when needed.
- Tier storage intelligently: Use cloud-native systems that automatically cache hot data in fast storage (like SSD or RAM) while keeping cold data in cost-effective object storage.
- Optimize refresh and maintenance: Tailor refresh rates, indexing, and compaction strategies for older data to minimize resource usage while ensuring analytics stay accurate and fast.
Get expert help migrating to Firebolt's columnar storage
## Common misconceptions about columnar storage
While columnar storage is a proven powerhouse for analytics, there are still a few myths that cause confusion — especially among teams new to modern data architectures. Let's break down the most common misconceptions and set the record straight:
### "It's only for big data"
| Reality | Example |
|---|---|
| Columnar storage shines with large datasets, but its benefits aren't exclusive to "big data" scale. Even with moderate data volumes, columnar systems can dramatically speed up analytics by scanning only the columns you need, compressing data efficiently, and minimizing I/O. | A startup analyzing customer engagement metrics (with just a few million records) can see 10x faster query times on a columnar warehouse like Firebolt compared to a traditional row-store database. |
### "It doesn't support real-time"
| Reality | Example |
|---|---|
| Early columnar systems were optimized mainly for batch analytics, but modern engines like Firebolt have shattered this limitation. Today's columnar databases can handle real-time or near-real-time analytics by combining fast ingestion with aggressive indexing and caching strategies. | Firebolt's sparse indexes and performance layer allow users to query freshly ingested data within seconds — enabling real-time dashboards, personalization engines, and operational reporting without compromising speed. |
### "It's not developer-friendly"
| Reality | Example |
|---|---|
| Modern columnar databases are designed to be highly developer-friendly, often speaking standard SQL and supporting familiar data modeling patterns. Many even offer integrations with major BI tools, orchestration platforms, and SDKs to make development seamless. | Firebolt supports ANSI-SQL, offers native SDKs, REST APIs, and integrates smoothly with dbt — allowing developers to build complex analytical apps and pipelines without learning proprietary languages or complex abstractions. |
## Conclusion
Columnar storage has transformed the way businesses approach analytics, unlocking faster query performance, greater scalability, and more efficient use of resources. By storing data by column instead of by row, organizations can dramatically reduce I/O, leverage compression, and accelerate analytical workloads — whether working with millions or billions of records.
As data volumes and user expectations continue to grow, adopting a columnar-first approach isn't just a performance boost — it's essential for building scalable, modern analytics platforms. Choosing the right columnar engine makes all the difference.
Firebolt sets itself apart with a proprietary file format, aggressive indexing strategies, and a cloud-native architecture built for extreme speed. With Firebolt, teams can power real-time analytics, deliver sub-second queries at massive scale, and optimize both cost and performance — all with a developer-friendly experience.
Ready to supercharge your analytics? See Firebolt's columnar engine in action
## FAQs
### What is columnar storage in a database?
Columnar storage is a method of organizing data so that each column is stored separately, rather than storing entire rows together. This design is particularly effective for analytical queries, where users often need to scan specific columns across large datasets.
Instead of reading every field in every row, a columnar database can read just the relevant columns, significantly reducing I/O and improving performance.
### How is columnar storage different from row storage?
In row-based storage, each row is stored as a single unit — ideal for transactional systems where entire records are frequently inserted, updated, or retrieved.
In contrast, columnar storage groups all values of a column together. This makes it more efficient for analytics because:
- Only needed columns are scanned (column pruning)
- Data compresses better (homogeneous values)
- Execution engines can process data in batches (vectorization)
Row storage is best for OLTP workloads (e.g., banking systems), while columnar storage excels in OLAP workloads (e.g., dashboards, reports, machine learning pipelines).
### Why is columnar storage faster?
Columnar storage is faster for analytical queries because it:
- Reads less data by scanning only relevant columns
- Uses better compression, shrinking the amount of data moved from disk to memory
- Supports vectorized execution, allowing CPUs to process multiple values in parallel
- Delays row reassembly (late materialization), optimizing memory usage and execution flow
Together, these optimizations reduce I/O, improve CPU efficiency, and deliver sub-second query performance on large datasets.
### What companies use columnar storage?
Columnar storage is widely adopted by companies that rely on analytics, business intelligence, or large-scale data processing. You'll find it powering:
- Cloud data warehouses like Firebolt, Amazon Redshift, Snowflake, and BigQuery
- BI tools like Apache Druid and ClickHouse
- Data lake engines like Apache Parquet and Apache ORC (used in Spark, Hive, etc.)
From startups to Fortune 500 companies, columnar storage is a foundational technology behind real-time dashboards, product analytics, and AI pipelines.
### How does Firebolt utilize columnar storage?
Firebolt is built from the ground up as a columnar-first cloud data warehouse, designed to deliver sub-second performance at scale. Its columnar engine powers key features like:
- Column pruning and predicate pushdown to minimize I/O
- Vectorized query execution for efficient in-memory processing
- High compression ratios to reduce storage and speed up scans
- Native indexing for fast data access
- Integration with Apache Iceberg, bringing columnar performance to lakehouse data