ON THIS PAGE
## Abstract
Similarweb, hosted on AWS, provides detailed analytics on how end customer audiences interact with websites. This requires ingestion and processing of large volumes of clickstream data in an AWS data lake on a daily basis. The challenges of performing segmentation analysis on big data combined with the need for sub-second end user response times for customer dashboards led Similarweb to evaluate modern analytics platforms. In this session, Similarweb and Firebolt, an AWS Technology Partner, will share how they delivered sub-second, high concurrency analytics cost effectively.
Firebolt's cloud-native architecture runs on AWS, enabling organizations like Similarweb to leverage Amazon Web Services' global infrastructure, elastic compute capabilities, and enterprise-grade security to power demanding analytics workloads at scale.
## About Similarweb
Imagine analyzing how the entire internet is used, like website analytics for all websites everywhere. That's Similarweb.
Similarweb is a big data powerhouse that collects enormous amounts of web-related data to help marketers, brands, salespeople, and other professionals analyze how audiences interact with websites. With SimilarWeb, you can easily track keyword searches that drive traffic to your site, identify which pages visitors land on, discover when they visit competitor websites instead, analyze their geographic location and mobile OS preferences, and determine whether they clicked organic or paid links.
#### The User Experience
The first thing visitors see on SimilarWeb is a search box for researching any website. For Similarweb, delivering an exceptional user experience where users can analyze, slice and dice, and extract insights through diverse analytical views is fundamental to their mission.
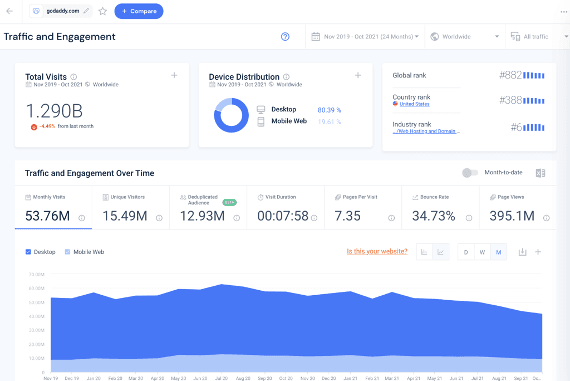
For example, users can see a comprehensive overview of godaddy.com's web behavior,
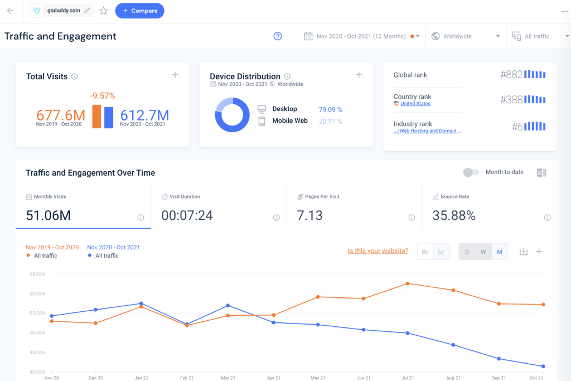
then dive deeper with additional analytical views:
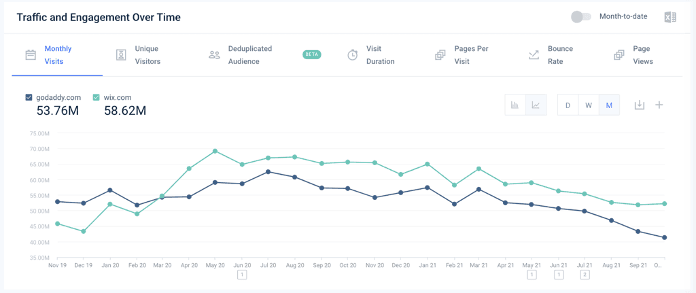
One particularly powerful feature allows head-to-head comparisons between multiple sites, such as godaddy.com versus wix.com.
#### The Technical Challenge
Delivering these experiences requires a purpose-built data stack that can simultaneously ingest, store, process, and analyze massive amounts of data while maintaining consistent performance.
## Similarweb's data architecture
Similarweb operates an AWS-based data lake that unifies raw datasets from multiple sources, including public data, partner feeds, and proprietary SimilarWeb collection methods. This centralized architecture enables efficient data processing, cleaning, and privacy protection in preparation for downstream analytics.
#### Processing Pipeline
The data pipeline centers on Spark and Airflow, ingesting 5TB of data daily. Machine learning models then analyze the cleansed data to create predictive insights, enabling SimilarWeb to draw conclusions about internet-wide behavior patterns from partial data points.
This foundational architecture supports diverse customer use cases across SimilarWeb's platform.
## The challenge of the 'Segment Analysis' use case
Imagine you're a marketer at FootLocker who wants to compare FootLocker.com's performance against Amazon.com. It's not an apples-to-apples comparison since Amazon sells much more than shoes, but both companies compete in the footwear market, so valuable insights exist.
Similarweb wanted to let users analyze specific segments within larger websites. This would allow comparing FootLocker.com traffic directly with shoe-related searches on Amazon.com. The company recognized this as one of their most analytically complex features ever.
#### The Technical Challenges
Similarweb faced several major hurdles:
Data Scale: The volumes are massive, making ETL processes costly and time-intensive to develop and maintain.
Dynamic User Input: Users can create exponentially complex combinations for comparison. Pre-processing every possible combination would be impossible.
Query Performance: Amazon alone generates 150GB of daily data in Similarweb's system. When users want to analyze two years of historical data using dynamic URL patterns, the system must scan enormous datasets. This becomes painfully slow, especially since multiple URLs are grouped into arrays for each user session.
## Solutions considered
Similarweb considered a number of technology solutions before they selected Firebolt
Presto: Similarweb initially considered Presto since they already used it for internal analytics. However, they quickly ruled it out because it couldn't deliver the sub-second latency required for a responsive end-user experience.
NoSQL Key-Value Databases: While these databases offer fast document storage, Similarweb rejected this approach because of poor SQL compatibility and lack of support for dynamic grouping operations.
Auto-Scaled Serverless Compute: Similarweb tested a more complex approach that would trigger one serverless function for each day in the user's query range. This solution had multiple fatal flaws:
- Storage Requirements: The approach required converting their existing ORC format data to JSON, essentially creating a full duplicate of their 1PB dataset to support all possible user segment requests.
- Performance Issues: Despite parallelization, some serverless functions consistently ran slower than others, creating unacceptable wait times for the overall query.
- Limited Functionality: The solution lacked SQL support for the additional grouping and aggregations that users needed.
## Selection of Firebolt
Firebolt is an analytical database that combines the cost and efficiency benefits of cloud-native architecture with sub-second performance at terabyte scale. It gives engineers the performance, flexibility, and control needed to power production-grade data and AI workloads.
#### Cloud-Native Architecture
Built on AWS, Firebolt uses decoupled storage and compute principles to eliminate traditional challenges around provisioning, scaling, and resource utilization. The platform leverages key AWS services including Amazon S3 for durable object storage and Amazon EKS with EC2 for elastic compute engines. This AWS-native approach ensures analytics solutions align with existing cloud strategy and security standards.
#### The Final Evaluation
Similarweb narrowed their choice to BigQuery and Firebolt, then conducted performance benchmarks. Firebolt emerged as the clear winner for several reasons:
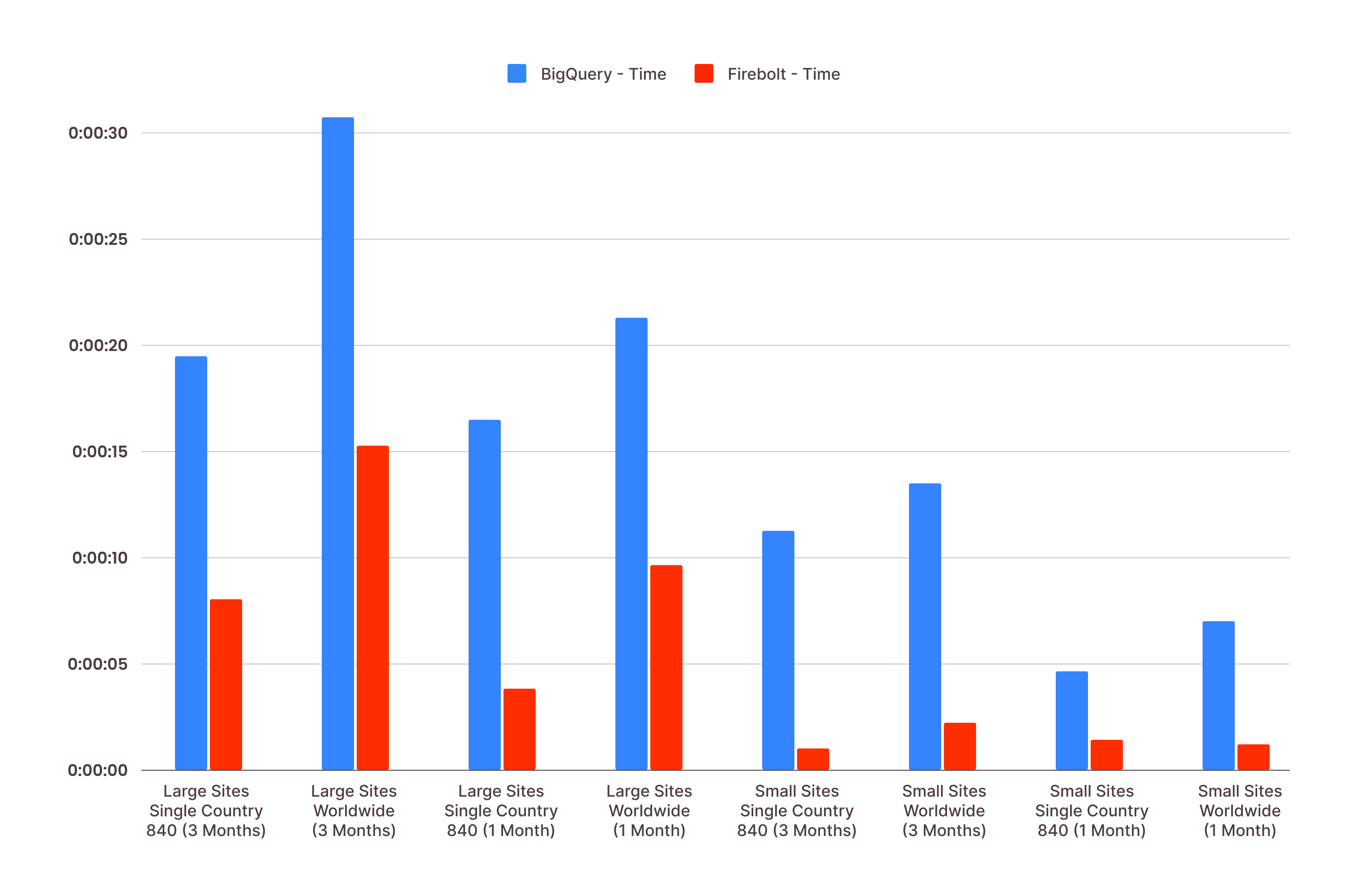
Superior Performance: Firebolt delivered the best results thanks to performance optimization engineering at every database layer. Importantly, it required no additional pre-processing—raw data could be loaded and immediately queried with sub-second performance.
Workload Isolation: The decoupled storage and compute architecture enabled easy workload isolation. Similarweb could isolate their new feature workloads to deliver consistently fast, predictable queries while continuing development on separate compute clusters (called "engines") without affecting production.
Cost Efficiency: Firebolt offered the best price-performance ratio and lowest total cost of ownership.
Rapid Implementation
Within weeks, Firebolt was fully integrated into production using Airflow and Firebolt's REST APIs. The platform now powers features like analyzing PlayStation 5 traffic patterns on Amazon.com—scanning multiple terabytes of data with dynamic "PS5" filtering while delivering ~1-second UI load times.
The seamless integration with Similarweb's existing AWS infrastructure enabled rapid deployment and immediate value realization.
For organizations looking to modernize their analytics infrastructure, Firebolt runs on AWS and is available through AWS Marketplace, providing a streamlined path to deploy high-performance analytics capabilities within existing AWS environments.